- Main
- FAQ
- Other questions
- How does using a robots.txt file affect Google indexing?
How does using a robots.txt file affect Google indexing?
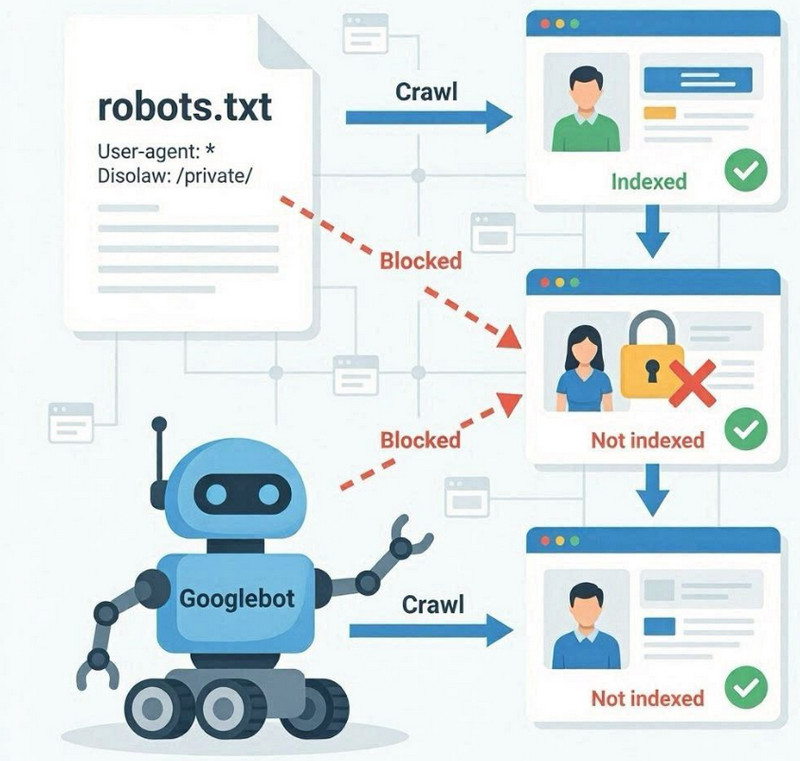
The robots.txt file is a technical file in the root of a website that sets rules for search engine bots regarding which sections can be crawled and which should be ignored. Its key function is to control crawling, not directly index pages.
When Googlebot accesses a website, it first checks robots.txt . If it specifies restrictions via the Disallow directive, the robot may not access certain sections or URLs. This means that such pages won't be crawled, meaning their content won't be fully processed for indexing.
The difference between crawling and indexing
Robots.txt doesn't directly prevent indexing. It restricts crawling access. This is an important distinction: a page may be known to Google through external links or internal mentions, but still not be crawled if access is denied.
In such cases, Google may keep the URL in the index without fully analyzing the content, which leads to limited or incorrect interpretation of the page in search.
Risks of incorrect configuration
Errors in robots.txt can significantly impact a website's visibility. If important sections, such as categories, product pages, or articles, are accidentally omitted, search engines won't be able to crawl them. This results in these pages being missing from the index or being incompletely indexed.
Blocking resources (CSS, JavaScript) is also a critical error, as it prevents the page from rendering correctly. This can result in Google's poor assessment of the quality and structure of content.
Using robots.txt to optimize crawling
When configured correctly, this file helps efficiently allocate crawl budget. Disabling service pages, filters, URL parameters, and duplicates allows the search engine to focus on the site's most important pages.
This is especially important for large sites where the number of pages can be in the thousands or millions, and a search engine physically cannot crawl them all in one cycle.
Thus, robots.txt influences indexing by controlling crawl access: it determines which pages Google can examine, and therefore which of them will potentially be indexed and included in search results.










