- Chủ yếu
- Câu hỏi thường gặp
- Các câu hỏi khác
- Việc sử dụng tệp robots.txt ảnh hưởng đến việc lập chỉ mục của Google như thế nào?
Việc sử dụng tệp robots.txt ảnh hưởng đến việc lập chỉ mục của Google như thế nào?
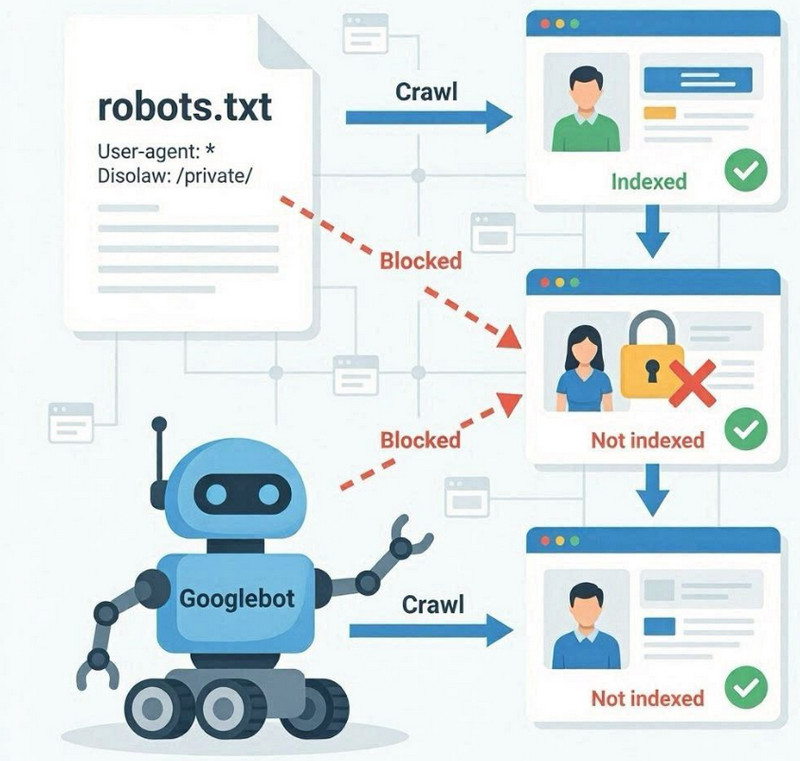
Tệp robots.txt là một tệp kỹ thuật nằm ở thư mục gốc của trang web, thiết lập các quy tắc cho các bot của công cụ tìm kiếm về việc phần nào được phép thu thập thông tin và phần nào nên bị bỏ qua. Chức năng chính của nó là kiểm soát việc thu thập thông tin, chứ không phải trực tiếp lập chỉ mục các trang.
Khi Googlebot truy cập một trang web, trước tiên nó sẽ kiểm tra tệp robots.txt. Nếu tệp này chỉ định các hạn chế thông qua chỉ thị Disallow , robot có thể không truy cập được vào một số phần hoặc URL nhất định. Điều này có nghĩa là các trang đó sẽ không được thu thập thông tin, tức là nội dung của chúng sẽ không được xử lý đầy đủ để lập chỉ mục.
Sự khác biệt giữa việc thu thập dữ liệu và lập chỉ mục
Tệp Robots.txt không trực tiếp ngăn chặn việc lập chỉ mục. Nó hạn chế quyền truy cập thu thập thông tin. Đây là một điểm khác biệt quan trọng: một trang có thể được Google biết đến thông qua các liên kết bên ngoài hoặc các đề cập nội bộ, nhưng vẫn không được thu thập thông tin nếu quyền truy cập bị từ chối.
Trong những trường hợp như vậy, Google có thể giữ URL trong chỉ mục mà không phân tích đầy đủ nội dung, dẫn đến việc hiểu sai hoặc hạn chế nội dung trang trong kết quả tìm kiếm.
Rủi ro do cấu hình sai
Lỗi trong tệp robots.txt có thể ảnh hưởng đáng kể đến khả năng hiển thị của một trang web. Nếu các phần quan trọng, chẳng hạn như danh mục, trang sản phẩm hoặc bài viết, vô tình bị bỏ sót, các công cụ tìm kiếm sẽ không thể thu thập thông tin về chúng. Điều này dẫn đến việc các trang này bị thiếu trong chỉ mục hoặc được lập chỉ mục không đầy đủ.
Việc chặn các tài nguyên (CSS, JavaScript) cũng là một lỗi nghiêm trọng, vì nó ngăn cản trang web hiển thị đúng cách. Điều này có thể dẫn đến việc Google đánh giá thấp chất lượng và cấu trúc nội dung.
Sử dụng robots.txt để tối ưu hóa quá trình thu thập dữ liệu.
Khi được cấu hình đúng cách, tệp này giúp phân bổ ngân sách thu thập dữ liệu một cách hiệu quả. Việc vô hiệu hóa các trang dịch vụ, bộ lọc, tham số URL và các trang trùng lặp cho phép công cụ tìm kiếm tập trung vào các trang quan trọng nhất của trang web.
Điều này đặc biệt quan trọng đối với các trang web lớn, nơi số lượng trang có thể lên đến hàng nghìn hoặc hàng triệu, và công cụ tìm kiếm không thể thu thập dữ liệu tất cả chúng trong một lần.
Như vậy, robots.txt ảnh hưởng đến việc lập chỉ mục bằng cách kiểm soát quyền truy cập thu thập dữ liệu: nó xác định những trang nào Google có thể xem xét, và do đó, trang nào trong số đó có khả năng được lập chỉ mục và đưa vào kết quả tìm kiếm.










