robots.txt ਫਾਈਲ ਦੀ ਵਰਤੋਂ ਗੂਗਲ ਇੰਡੈਕਸਿੰਗ ਨੂੰ ਕਿਵੇਂ ਪ੍ਰਭਾਵਿਤ ਕਰਦੀ ਹੈ?
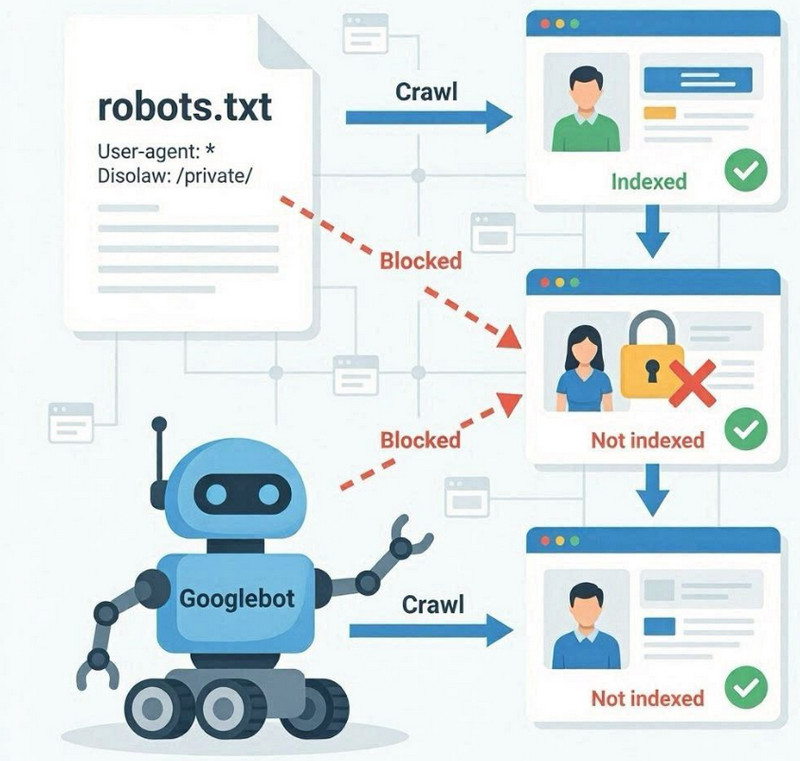
robots.txt ਫਾਈਲ ਇੱਕ ਵੈੱਬਸਾਈਟ ਦੇ ਰੂਟ ਵਿੱਚ ਇੱਕ ਤਕਨੀਕੀ ਫਾਈਲ ਹੈ ਜੋ ਖੋਜ ਇੰਜਣ ਬੋਟਾਂ ਲਈ ਨਿਯਮ ਨਿਰਧਾਰਤ ਕਰਦੀ ਹੈ ਕਿ ਕਿਹੜੇ ਭਾਗਾਂ ਨੂੰ ਕ੍ਰੌਲ ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ ਅਤੇ ਕਿਹੜੇ ਨੂੰ ਅਣਡਿੱਠਾ ਕੀਤਾ ਜਾਣਾ ਚਾਹੀਦਾ ਹੈ। ਇਸਦਾ ਮੁੱਖ ਕੰਮ ਕ੍ਰੌਲਿੰਗ ਨੂੰ ਕੰਟਰੋਲ ਕਰਨਾ ਹੈ, ਸਿੱਧੇ ਪੰਨਿਆਂ ਨੂੰ ਇੰਡੈਕਸ ਕਰਨਾ ਨਹੀਂ।
ਜਦੋਂ Googlebot ਕਿਸੇ ਵੈੱਬਸਾਈਟ ਨੂੰ ਐਕਸੈਸ ਕਰਦਾ ਹੈ, ਤਾਂ ਇਹ ਪਹਿਲਾਂ robots.txt ਦੀ ਜਾਂਚ ਕਰਦਾ ਹੈ। ਜੇਕਰ ਇਹ Disallow ਨਿਰਦੇਸ਼ ਰਾਹੀਂ ਪਾਬੰਦੀਆਂ ਨਿਰਧਾਰਤ ਕਰਦਾ ਹੈ, ਤਾਂ ਰੋਬੋਟ ਕੁਝ ਭਾਗਾਂ ਜਾਂ URL ਤੱਕ ਪਹੁੰਚ ਨਹੀਂ ਕਰ ਸਕਦਾ। ਇਸਦਾ ਮਤਲਬ ਹੈ ਕਿ ਅਜਿਹੇ ਪੰਨਿਆਂ ਨੂੰ ਕ੍ਰੌਲ ਨਹੀਂ ਕੀਤਾ ਜਾਵੇਗਾ, ਭਾਵ ਉਹਨਾਂ ਦੀ ਸਮੱਗਰੀ ਨੂੰ ਇੰਡੈਕਸਿੰਗ ਲਈ ਪੂਰੀ ਤਰ੍ਹਾਂ ਪ੍ਰੋਸੈਸ ਨਹੀਂ ਕੀਤਾ ਜਾਵੇਗਾ।
ਕ੍ਰੌਲਿੰਗ ਅਤੇ ਇੰਡੈਕਸਿੰਗ ਵਿੱਚ ਅੰਤਰ
Robots.txt ਸਿੱਧੇ ਤੌਰ 'ਤੇ ਇੰਡੈਕਸਿੰਗ ਨੂੰ ਨਹੀਂ ਰੋਕਦਾ। ਇਹ ਕ੍ਰੌਲਿੰਗ ਪਹੁੰਚ ਨੂੰ ਸੀਮਤ ਕਰਦਾ ਹੈ। ਇਹ ਇੱਕ ਮਹੱਤਵਪੂਰਨ ਅੰਤਰ ਹੈ: ਇੱਕ ਪੰਨਾ Google ਨੂੰ ਬਾਹਰੀ ਲਿੰਕਾਂ ਜਾਂ ਅੰਦਰੂਨੀ ਜ਼ਿਕਰਾਂ ਰਾਹੀਂ ਜਾਣਿਆ ਜਾ ਸਕਦਾ ਹੈ, ਪਰ ਜੇਕਰ ਪਹੁੰਚ ਤੋਂ ਇਨਕਾਰ ਕੀਤਾ ਜਾਂਦਾ ਹੈ ਤਾਂ ਫਿਰ ਵੀ ਇਸਨੂੰ ਕ੍ਰੌਲ ਨਹੀਂ ਕੀਤਾ ਜਾ ਸਕਦਾ।
ਅਜਿਹੇ ਮਾਮਲਿਆਂ ਵਿੱਚ, ਗੂਗਲ ਸਮੱਗਰੀ ਦਾ ਪੂਰੀ ਤਰ੍ਹਾਂ ਵਿਸ਼ਲੇਸ਼ਣ ਕੀਤੇ ਬਿਨਾਂ URL ਨੂੰ ਸੂਚਕਾਂਕ ਵਿੱਚ ਰੱਖ ਸਕਦਾ ਹੈ, ਜਿਸ ਨਾਲ ਖੋਜ ਵਿੱਚ ਪੰਨੇ ਦੀ ਸੀਮਤ ਜਾਂ ਗਲਤ ਵਿਆਖਿਆ ਹੁੰਦੀ ਹੈ।
ਗਲਤ ਸੰਰਚਨਾ ਦੇ ਜੋਖਮ
robots.txt ਵਿੱਚ ਗਲਤੀਆਂ ਵੈੱਬਸਾਈਟ ਦੀ ਦਿੱਖ ਨੂੰ ਕਾਫ਼ੀ ਪ੍ਰਭਾਵਿਤ ਕਰ ਸਕਦੀਆਂ ਹਨ। ਜੇਕਰ ਮਹੱਤਵਪੂਰਨ ਭਾਗ, ਜਿਵੇਂ ਕਿ ਸ਼੍ਰੇਣੀਆਂ, ਉਤਪਾਦ ਪੰਨੇ, ਜਾਂ ਲੇਖ, ਗਲਤੀ ਨਾਲ ਛੱਡ ਦਿੱਤੇ ਜਾਂਦੇ ਹਨ, ਤਾਂ ਖੋਜ ਇੰਜਣ ਉਹਨਾਂ ਨੂੰ ਕ੍ਰੌਲ ਨਹੀਂ ਕਰ ਸਕਣਗੇ। ਇਸ ਦੇ ਨਤੀਜੇ ਵਜੋਂ ਇਹ ਪੰਨੇ ਸੂਚਕਾਂਕ ਤੋਂ ਗਾਇਬ ਹੋ ਜਾਂਦੇ ਹਨ ਜਾਂ ਅਧੂਰੇ ਤੌਰ 'ਤੇ ਸੂਚਕਾਂਕ ਕੀਤੇ ਜਾਂਦੇ ਹਨ।
ਸਰੋਤਾਂ (CSS, JavaScript) ਨੂੰ ਬਲੌਕ ਕਰਨਾ ਵੀ ਇੱਕ ਗੰਭੀਰ ਗਲਤੀ ਹੈ, ਕਿਉਂਕਿ ਇਹ ਪੰਨੇ ਨੂੰ ਸਹੀ ਢੰਗ ਨਾਲ ਪੇਸ਼ ਕਰਨ ਤੋਂ ਰੋਕਦੀ ਹੈ। ਇਸ ਦੇ ਨਤੀਜੇ ਵਜੋਂ Google ਸਮੱਗਰੀ ਦੀ ਗੁਣਵੱਤਾ ਅਤੇ ਬਣਤਰ ਦਾ ਮਾੜਾ ਮੁਲਾਂਕਣ ਕਰ ਸਕਦਾ ਹੈ।
ਕ੍ਰੌਲਿੰਗ ਨੂੰ ਅਨੁਕੂਲ ਬਣਾਉਣ ਲਈ robots.txt ਦੀ ਵਰਤੋਂ ਕਰਨਾ
ਜਦੋਂ ਸਹੀ ਢੰਗ ਨਾਲ ਕੌਂਫਿਗਰ ਕੀਤਾ ਜਾਂਦਾ ਹੈ, ਤਾਂ ਇਹ ਫਾਈਲ ਕ੍ਰੌਲ ਬਜਟ ਨੂੰ ਕੁਸ਼ਲਤਾ ਨਾਲ ਨਿਰਧਾਰਤ ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰਦੀ ਹੈ। ਸੇਵਾ ਪੰਨਿਆਂ, ਫਿਲਟਰਾਂ, URL ਪੈਰਾਮੀਟਰਾਂ ਅਤੇ ਡੁਪਲੀਕੇਟਸ ਨੂੰ ਅਯੋਗ ਕਰਨ ਨਾਲ ਖੋਜ ਇੰਜਣ ਸਾਈਟ ਦੇ ਸਭ ਤੋਂ ਮਹੱਤਵਪੂਰਨ ਪੰਨਿਆਂ 'ਤੇ ਧਿਆਨ ਕੇਂਦਰਿਤ ਕਰ ਸਕਦਾ ਹੈ।
ਇਹ ਖਾਸ ਤੌਰ 'ਤੇ ਵੱਡੀਆਂ ਸਾਈਟਾਂ ਲਈ ਮਹੱਤਵਪੂਰਨ ਹੈ ਜਿੱਥੇ ਪੰਨਿਆਂ ਦੀ ਗਿਣਤੀ ਹਜ਼ਾਰਾਂ ਜਾਂ ਲੱਖਾਂ ਵਿੱਚ ਹੋ ਸਕਦੀ ਹੈ, ਅਤੇ ਇੱਕ ਖੋਜ ਇੰਜਣ ਸਰੀਰਕ ਤੌਰ 'ਤੇ ਉਹਨਾਂ ਸਾਰਿਆਂ ਨੂੰ ਇੱਕ ਚੱਕਰ ਵਿੱਚ ਨਹੀਂ ਕਰ ਸਕਦਾ।
ਇਸ ਤਰ੍ਹਾਂ, robots.txt ਕ੍ਰੌਲ ਐਕਸੈਸ ਨੂੰ ਨਿਯੰਤਰਿਤ ਕਰਕੇ ਇੰਡੈਕਸਿੰਗ ਨੂੰ ਪ੍ਰਭਾਵਿਤ ਕਰਦਾ ਹੈ: ਇਹ ਨਿਰਧਾਰਤ ਕਰਦਾ ਹੈ ਕਿ Google ਕਿਹੜੇ ਪੰਨਿਆਂ ਦੀ ਜਾਂਚ ਕਰ ਸਕਦਾ ਹੈ, ਅਤੇ ਇਸ ਲਈ ਉਹਨਾਂ ਵਿੱਚੋਂ ਕਿਹੜੇ ਪੰਨਿਆਂ ਨੂੰ ਸੰਭਾਵੀ ਤੌਰ 'ਤੇ ਇੰਡੈਕਸ ਕੀਤਾ ਜਾਵੇਗਾ ਅਤੇ ਖੋਜ ਨਤੀਜਿਆਂ ਵਿੱਚ ਸ਼ਾਮਲ ਕੀਤਾ ਜਾਵੇਗਾ।










