- ਮੁੱਖ
- FAQ
- ਇੰਡੈਕਸਿੰਗ ਬਾਰੇ ਆਮ ਸਵਾਲ
- ਵੈੱਬਸਾਈਟ ਪੰਨਿਆਂ ਨੂੰ ਲੰਬੇ ਸਮੇਂ ਲਈ ਇੰਡੈਕਸ ਕਿਉਂ ਨਹੀਂ ਕੀਤਾ ਜਾ ਸਕਦਾ?
ਵੈੱਬਸਾਈਟ ਪੰਨਿਆਂ ਨੂੰ ਲੰਬੇ ਸਮੇਂ ਲਈ ਇੰਡੈਕਸ ਕਿਉਂ ਨਹੀਂ ਕੀਤਾ ਜਾ ਸਕਦਾ?
ਵੈੱਬਸਾਈਟ ਪੰਨੇ ਕਈ ਕਾਰਨਾਂ ਕਰਕੇ ਲੰਬੇ ਸਮੇਂ ਤੱਕ ਇੰਡੈਕਸ ਰਹਿ ਸਕਦੇ ਹਨ, ਅਤੇ ਜ਼ਿਆਦਾਤਰ ਮਾਮਲਿਆਂ ਵਿੱਚ, ਇਹ ਇੱਕ ਮੁੱਦਾ ਨਹੀਂ ਹੈ ਬਲਕਿ ਕਾਰਕਾਂ ਦਾ ਸੁਮੇਲ ਹੈ। ਗੂਗਲ ਜਾਂ ਯਾਂਡੇਕਸ ਵਰਗੇ ਖੋਜ ਇੰਜਣਾਂ ਨੂੰ ਹਰ ਪੰਨੇ ਨੂੰ ਇੰਡੈਕਸ ਕਰਨ ਦੀ ਲੋੜ ਨਹੀਂ ਹੁੰਦੀ ਹੈ ਜੋ ਉਹ ਲੱਭਦੇ ਹਨ - ਉਹ ਸਿਰਫ਼ ਉਹਨਾਂ URLs ਦੀ ਚੋਣ ਕਰਦੇ ਹਨ ਜਿਨ੍ਹਾਂ ਨੂੰ ਉਹ ਉਪਯੋਗੀ ਅਤੇ ਉੱਚ-ਗੁਣਵੱਤਾ ਸਮਝਦੇ ਹਨ।
ਸਭ ਤੋਂ ਆਮ ਕਾਰਨਾਂ ਵਿੱਚੋਂ ਇੱਕ ਕਮਜ਼ੋਰ ਅੰਦਰੂਨੀ ਲਿੰਕਿੰਗ ਹੈ। ਜੇਕਰ ਕਿਸੇ ਪੰਨੇ ਨੂੰ ਸਾਈਟ ਦੇ ਦੂਜੇ ਭਾਗਾਂ ਤੋਂ ਲਿੰਕ ਨਹੀਂ ਕੀਤਾ ਜਾਂਦਾ ਹੈ, ਤਾਂ ਖੋਜ ਇੰਜਣਾਂ ਲਈ ਇਸਨੂੰ ਖੋਜਣਾ ਅਤੇ ਇਸਦੀ ਮਹੱਤਤਾ ਨੂੰ ਸਮਝਣਾ ਔਖਾ ਹੁੰਦਾ ਹੈ। ਅਜਿਹੇ ਪੰਨੇ ਅਕਸਰ ਬਿਨਾਂ ਕਿਸੇ ਖੋਜ ਇੰਜਣ ਰੈਂਕਿੰਗ ਸ਼ਕਤੀ ਦੇ, ਵਿਹਲੇ ਰਹਿੰਦੇ ਹਨ, ਅਤੇ ਲੰਬੇ ਸਮੇਂ ਲਈ ਅਣਡਿੱਠੇ ਕੀਤੇ ਜਾ ਸਕਦੇ ਹਨ।
ਦੂਜਾ ਮਹੱਤਵਪੂਰਨ ਕਾਰਕ ਕ੍ਰੌਲ ਬਜਟ ਹੈ। ਹਰੇਕ ਵੈੱਬਸਾਈਟ ਕੋਲ ਸੀਮਤ ਮਾਤਰਾ ਵਿੱਚ ਸਰੋਤ ਹੁੰਦੇ ਹਨ ਜੋ ਖੋਜ ਇੰਜਣ ਇਸਨੂੰ ਕ੍ਰੌਲ ਕਰਨ 'ਤੇ ਖਰਚ ਕਰਨ ਲਈ ਤਿਆਰ ਹੁੰਦੇ ਹਨ। ਜੇਕਰ ਕਿਸੇ ਸਾਈਟ ਵਿੱਚ ਹਜ਼ਾਰਾਂ ਜਾਂ ਲੱਖਾਂ URL ਹਨ (ਉਦਾਹਰਣ ਵਜੋਂ, ਫਿਲਟਰ, ਪੈਰਾਮੀਟਰ, ਡੁਪਲੀਕੇਟ), ਤਾਂ ਕ੍ਰੌਲਰ ਘੱਟ ਮਹੱਤਵਪੂਰਨ ਪੰਨਿਆਂ 'ਤੇ ਸਮਾਂ ਬਰਬਾਦ ਕਰ ਸਕਦਾ ਹੈ, ਉਹਨਾਂ ਨੂੰ ਗੁਆ ਸਕਦਾ ਹੈ ਜਿਨ੍ਹਾਂ ਦੀ ਉਸਨੂੰ ਲੋੜ ਹੁੰਦੀ ਹੈ। ਨਤੀਜੇ ਵਜੋਂ, ਕੁਝ URL ਜਾਂ ਤਾਂ ਦੇਰੀ ਨਾਲ ਆਉਂਦੇ ਹਨ ਜਾਂ ਪੂਰੀ ਤਰ੍ਹਾਂ ਅਣਡਿੱਠ ਕੀਤੇ ਜਾਂਦੇ ਹਨ।
ਤਕਨੀਕੀ ਗਲਤੀਆਂ ਇੱਕ ਹੋਰ ਆਮ ਕਾਰਨ ਹਨ। ਜੇਕਰ ਕੋਈ ਪੰਨਾ ਇੱਕ ਅਸਥਿਰ ਸਰਵਰ ਜਵਾਬ ਦਿੰਦਾ ਹੈ, ਲੋਡ ਹੋਣ ਵਿੱਚ ਲੰਮਾ ਸਮਾਂ ਲੈਂਦਾ ਹੈ, HTML ਗਲਤੀਆਂ ਰੱਖਦਾ ਹੈ, ਜਾਂ ਵਿਰੋਧੀ ਨਿਰਦੇਸ਼ ਰੱਖਦਾ ਹੈ (ਉਦਾਹਰਣ ਵਜੋਂ, ਇੱਕ ਕੈਨੋਨੀਕਲ URL ਇੱਕ ਵੱਖਰੇ URL ਵੱਲ ਇਸ਼ਾਰਾ ਕਰਦਾ ਹੈ ਜਦੋਂ ਪੰਨਾ ਇੰਡੈਕਸਿੰਗ ਲਈ ਖੁੱਲ੍ਹਾ ਹੁੰਦਾ ਹੈ), ਤਾਂ ਖੋਜ ਇੰਜਣ ਆਪਣੀ ਇੰਡੈਕਸਿੰਗ ਵਿੱਚ ਦੇਰੀ ਜਾਂ ਰੱਦ ਕਰ ਸਕਦਾ ਹੈ। Robots.txt ਪਾਬੰਦੀਆਂ ਜਾਂ noindex ਮੈਟਾ ਟੈਗ ਦਾ ਵੀ ਇਸੇ ਤਰ੍ਹਾਂ ਦਾ ਪ੍ਰਭਾਵ ਹੁੰਦਾ ਹੈ।
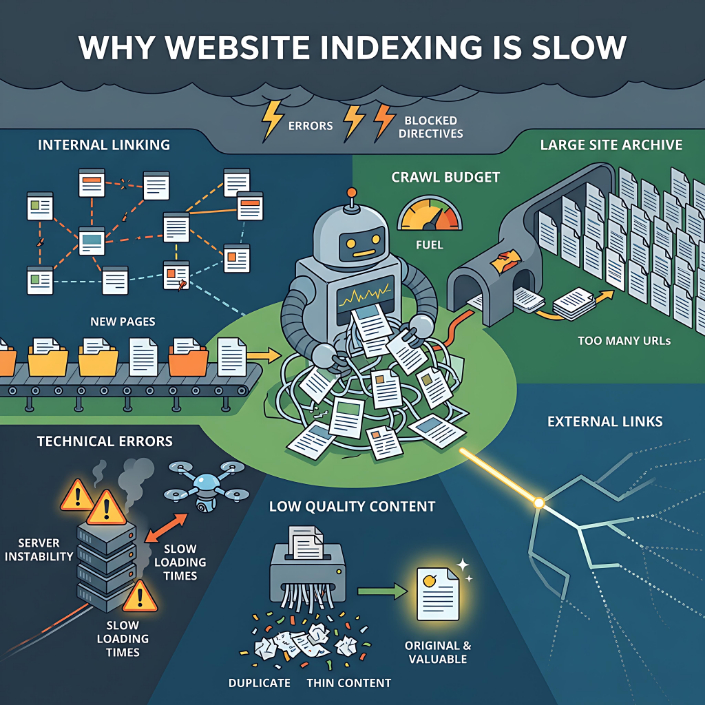
ਸਮੱਗਰੀ ਦੀ ਗੁਣਵੱਤਾ ਵਿਸ਼ੇਸ਼ ਧਿਆਨ ਦੇ ਹੱਕਦਾਰ ਹੈ। ਭਾਵੇਂ ਕੋਈ ਪੰਨਾ ਪਹੁੰਚਯੋਗ ਅਤੇ ਤਕਨੀਕੀ ਤੌਰ 'ਤੇ ਸਹੀ ਢੰਗ ਨਾਲ ਸੰਰਚਿਤ ਹੈ, ਪਰ ਜੇਕਰ ਖੋਜ ਇੰਜਣ ਇਸਨੂੰ ਘੱਟ ਉਪਯੋਗੀ ਸਮਝਦਾ ਹੈ ਤਾਂ ਇਸਨੂੰ ਸੂਚੀਬੱਧ ਨਹੀਂ ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ। ਇਹ ਡੁਪਲੀਕੇਟ ਪੰਨਿਆਂ, ਆਪਣੇ ਆਪ ਤਿਆਰ ਕੀਤੀ ਸਮੱਗਰੀ, ਘੱਟੋ-ਘੱਟ ਜਾਣਕਾਰੀ ਵਾਲੇ ਪਤਲੇ ਸਮੱਗਰੀ ਪੰਨਿਆਂ, ਜਾਂ ਵਿਲੱਖਣ ਵਰਣਨ ਤੋਂ ਬਿਨਾਂ ਆਮ ਉਤਪਾਦ ਪੰਨਿਆਂ 'ਤੇ ਲਾਗੂ ਹੁੰਦਾ ਹੈ। ਅਜਿਹੇ ਮਾਮਲਿਆਂ ਵਿੱਚ, ਖੋਜ ਇੰਜਣ ਪੰਨੇ ਨੂੰ ਕ੍ਰੌਲ ਕਰ ਸਕਦਾ ਹੈ ਪਰ ਇਸਨੂੰ ਸੂਚੀ-ਪੱਤਰ ਵਿੱਚ ਸ਼ਾਮਲ ਨਹੀਂ ਕਰ ਸਕਦਾ।
ਬਾਹਰੀ ਸਿਗਨਲ ਵੀ ਮਹੱਤਵਪੂਰਨ ਹਨ। ਜੇਕਰ ਕਿਸੇ ਪੰਨੇ ਦੇ ਕੋਈ ਬਾਹਰੀ ਲਿੰਕ ਨਹੀਂ ਹਨ ਅਤੇ ਸਾਈਟ ਤੋਂ ਬਾਹਰ ਜ਼ਿਕਰ ਨਹੀਂ ਕੀਤਾ ਗਿਆ ਹੈ, ਤਾਂ ਤੇਜ਼ੀ ਨਾਲ ਇੰਡੈਕਸਿੰਗ ਦੀ ਸੰਭਾਵਨਾ ਘੱਟ ਜਾਂਦੀ ਹੈ। ਖੋਜ ਇੰਜਣ ਪੰਨਿਆਂ ਦੀ ਮਹੱਤਤਾ ਦਾ ਪਤਾ ਲਗਾਉਣ ਅਤੇ ਮੁਲਾਂਕਣ ਕਰਨ ਲਈ ਲਿੰਕਾਂ ਨੂੰ ਇੱਕ ਮੁੱਖ ਸੰਕੇਤ ਵਜੋਂ ਵਰਤਦੇ ਹਨ।
ਇੰਡੈਕਸਿੰਗ ਸਮੱਸਿਆਵਾਂ ਖਾਸ ਤੌਰ 'ਤੇ ਗੁੰਝਲਦਾਰ ਢਾਂਚੇ ਵਾਲੀਆਂ ਵੈੱਬਸਾਈਟਾਂ ਵਿੱਚ ਆਮ ਹਨ, ਜਿਵੇਂ ਕਿ ਔਨਲਾਈਨ ਸਟੋਰ, ਕੈਟਾਲਾਗ, ਐਗਰੀਗੇਟਰ, ਅਤੇ ਨਿਊਜ਼ ਪ੍ਰੋਜੈਕਟ। ਉਨ੍ਹਾਂ ਕੋਲ ਬਹੁਤ ਸਾਰੇ ਸਮਾਨ ਪੰਨੇ, ਫਿਲਟਰ, URL ਭਿੰਨਤਾਵਾਂ, ਅਤੇ ਗਤੀਸ਼ੀਲ ਸਮੱਗਰੀ ਹੈ। ਇਹ ਕ੍ਰੌਲਰਾਂ 'ਤੇ ਭਾਰ ਪੈਦਾ ਕਰਦਾ ਹੈ ਅਤੇ ਡੁਪਲੀਕੇਟ ਦਾ ਜੋਖਮ ਵਧਾਉਂਦਾ ਹੈ। ਨੌਜਵਾਨ ਵੈੱਬਸਾਈਟਾਂ ਨੂੰ ਵੀ ਇਸੇ ਤਰ੍ਹਾਂ ਦੀ ਸਥਿਤੀ ਦਾ ਸਾਹਮਣਾ ਕਰਨਾ ਪੈਂਦਾ ਹੈ—ਉਨ੍ਹਾਂ ਨੇ ਅਜੇ ਤੱਕ ਖੋਜ ਇੰਜਣਾਂ ਨਾਲ ਵਿਸ਼ਵਾਸ ਸਥਾਪਿਤ ਨਹੀਂ ਕੀਤਾ ਹੈ, ਇਸ ਲਈ ਇੰਡੈਕਸਿੰਗ ਹੌਲੀ ਹੋ ਸਕਦੀ ਹੈ।
ਇਸ ਤੋਂ ਇਲਾਵਾ, ਇੱਕੋ ਸਮੇਂ ਵੱਡੀ ਗਿਣਤੀ ਵਿੱਚ ਨਵੇਂ URL ਜੋੜੇ ਜਾਣ ਨਾਲ ਵੀ ਪ੍ਰਕਿਰਿਆ ਹੌਲੀ ਹੋ ਸਕਦੀ ਹੈ। ਖੋਜ ਇੰਜਣ ਹਮੇਸ਼ਾ ਇੱਕੋ ਸਮੇਂ ਹਰ ਚੀਜ਼ ਦੀ ਪ੍ਰਕਿਰਿਆ ਨਹੀਂ ਕਰਦੇ; ਉਹ ਸਰੋਤਾਂ ਨੂੰ ਹੌਲੀ-ਹੌਲੀ ਵੰਡਦੇ ਹਨ, ਖਾਸ ਕਰਕੇ ਜੇਕਰ ਸਾਈਟ ਨੇ ਪਹਿਲਾਂ ਇਕਸਾਰ ਗੁਣਵੱਤਾ ਦਾ ਪ੍ਰਦਰਸ਼ਨ ਨਹੀਂ ਕੀਤਾ ਹੈ।
ਅੰਤ ਵਿੱਚ, ਹੌਲੀ ਇੰਡੈਕਸਿੰਗ ਇੱਕ ਸੰਕੇਤ ਹੈ ਕਿ ਖੋਜ ਇੰਜਣ ਨੂੰ ਜਾਂ ਤਾਂ ਪੰਨੇ ਤੱਕ ਪਹੁੰਚਣ ਵਿੱਚ ਮੁਸ਼ਕਲ ਆ ਰਹੀ ਹੈ ਜਾਂ ਉਸਨੂੰ ਇਸ ਵਿੱਚ ਕਾਫ਼ੀ ਮੁੱਲ ਨਹੀਂ ਦਿਖਾਈ ਦੇ ਰਿਹਾ ਹੈ। ਇਸ ਲਈ, ਇੱਕ ਪ੍ਰਭਾਵਸ਼ਾਲੀ ਰਣਨੀਤੀ ਸਿਰਫ਼ ਇੰਡੈਕਸਿੰਗ ਲਈ URL ਨੂੰ "ਪੁਸ਼" ਕਰਨਾ ਨਹੀਂ ਹੈ, ਸਗੋਂ ਸਮੱਗਰੀ ਦੀ ਗੁਣਵੱਤਾ, ਸਾਈਟ ਬਣਤਰ, ਇੰਟਰਲਿੰਕਿੰਗ ਅਤੇ ਤਕਨੀਕੀ ਸਥਿਤੀ ਨੂੰ ਵੀ ਸੰਬੋਧਿਤ ਕਰਨਾ ਹੈ।










