为什么有些网页长时间无法被索引?
- 关于索引的常见问题
- 2index.ninja 的工作原理
- 网站页面索引
- 反向链接索引
- 检查谷歌索引
- 关税、代币和支付
- API 和批量工作
- 保证、期限和结果
- 安全与限制
- 技术问题
-
其他问题
- 如何在反向链接获取策略中使用竞争对手跟踪?
- 内容在吸引反向链接方面有多重要?
- 如何确保良好的页面加载速度,从而实现更好的索引和优化?
- 哪些页面优化建议有助于提高它们的索引排名?
- 如何查看哪些页面已被搜索引擎收录?
- 内部链接如何帮助优化 Yandex 索引?
- 快速索引如何影响搜索结果排名?
- 如何监控指向您网站的外部链接的质量?
- 有哪些方法可以用来寻找潜在的反向链接来源?
- 有哪些工具可用于反向链接监控?
- 如何评估反向链接的质量?
- 优化网站加载速度对 Yandex 索引有何影响?
- 使用 robots.txt 文件会对 Google 索引产生什么影响?
- 为了提高Yandex的索引效果,可以采取哪些具体的优化建议?
- 如何评估其他网站资源的域名权威性和页面权威性?
- 如何查看您的移动网站哪些页面已被 Google 收录?
- 如何为特定页面选择合适的关键词?
- 在优化搜索引擎排名以实现快速索引时,如何考虑页面加载速度?
- 内容长度如何影响页面索引和排名?
- 网站页面索引服务有哪些好处?
- 什么是规范网址?它在搜索引擎优化(SEO)中是如何使用的?
- 提高谷歌索引质量的基本步骤有哪些?
- 如何确保您的网站对谷歌移动设备友好?
- 如何创建网站地图并提交给谷歌?
- 如何加快新网页的索引速度?
- 社交信号如何影响搜索引擎优化?
- 如何为你的网站选择合适的关键词?
- 在吸引反向链接时应该避免哪些错误?
- 如何将内容营销应用于反向链接获取策略?
- 评估反向链接获取策略的有效性时,应该跟踪哪些指标?
- 锚文本在反向链接获取策略中扮演什么角色?
- 反向链接有哪些类型?
- 吸引反向链接有什么好处?
- 社交媒体在搜索引擎优化(SEO)中扮演什么角色?
- 什么是长尾关键词?它们在搜索引擎优化(SEO)中是如何使用的?
- 从搜索引擎优化(SEO)的角度来看,什么样的内容才算优质内容?
- 如何衡量SEO效果?应该追踪哪些指标?
- 什么是自然搜索?
- 什么是网站地图?它如何帮助搜索引擎优化?
- 什么是网络爬虫?它与索引有什么关系?
- 可以使用哪些SEO分析工具?
- 什么是反向链接(外部链接)?它们如何影响搜索引擎优化(SEO)?
- 影响网站加载速度的因素有哪些?为什么网站加载速度对搜索引擎优化(SEO)很重要?
- SEO中的关键词是什么?
- 什么是元标签?它们如何影响搜索引擎优化?
- 什么是SEO(搜索引擎优化)?
- Yandex.Webmaster 是什么?
- 什么是 Google Search Console?
- 什么是有效链接?
- 搜索引擎如何找到新的网页?
- 如何查看结果
- 索引需要多长时间?
- 这是如何运作的
- 费用是多少?
- 所有页面和链接都会被索引吗?
网站页面可能由于各种原因长时间未被搜索引擎收录,而且大多数情况下,这并非单一因素造成的,而是多种因素共同作用的结果。像谷歌或Yandex这样的搜索引擎并没有义务收录它们找到的每个页面——它们只会选择那些它们认为有用且高质量的网址。
最常见的原因之一是内部链接薄弱。如果一个页面没有被网站其他部分链接到,搜索引擎就很难发现它,也难以理解它的重要性。这样的页面往往会闲置,没有任何搜索引擎排名加分,并且可能长期被忽视。
第二个重要因素是抓取预算。每个网站都拥有有限的资源,搜索引擎愿意将这些资源用于抓取。如果一个网站有成千上万个URL(例如,过滤器、参数、重复项),抓取工具可能会将时间浪费在不太重要的页面上,从而错过真正需要的页面。结果,一些URL要么被延迟抓取,要么被完全忽略。
技术错误是另一个常见原因。如果页面返回不稳定的服务器响应、加载时间过长、包含 HTML 错误或包含冲突的指令(例如,规范 URL 指向不同的 URL,而页面已开放索引),搜索引擎可能会延迟或取消索引。robots.txt 限制或 noindex 元标签也会产生类似的效果。
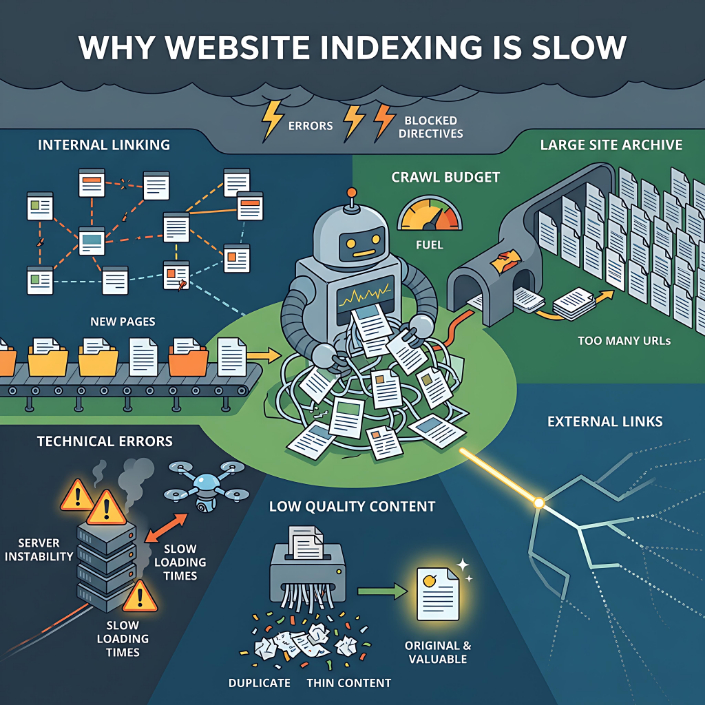
内容质量值得特别关注。即使页面可访问且技术配置正确,如果搜索引擎认为其价值不大,则可能不会将其编入索引。这适用于重复页面、自动生成的内容、信息量极少的单薄页面,或缺乏独特描述的通用产品页面。在这种情况下,搜索引擎可能会抓取页面,但不会将其添加到索引中。
外部信号也很重要。如果一个页面没有外部链接,也没有在网站之外被提及,那么它被快速索引的可能性就会降低。搜索引擎会将链接作为检测和评估页面重要性的关键信号之一。
索引问题在结构复杂的网站中尤为常见,例如在线商店、产品目录、聚合网站和新闻网站。这类网站拥有大量相似页面、筛选器、URL变体和动态内容。这会给搜索引擎爬虫带来沉重的负担,并增加重复条目的风险。新网站也面临类似的情况——它们尚未与搜索引擎建立信任,因此索引速度可能较慢。
此外,同时添加大量新网址也会减慢处理速度。搜索引擎并非总是一次性处理所有内容;它们会逐步分配资源,尤其是在网站之前质量不稳定的情况下。
归根结底,索引速度慢表明搜索引擎要么难以访问该页面,要么认为该页面价值不足。因此,有效的策略并非仅仅是“推送”URL以进行索引,而是要同时关注内容质量、网站结构、内部链接和技术状况。










