- Principal
- FAQ
- Questions générales sur l'indexation
- Pourquoi certaines pages web peuvent-elles ne pas être indexées pendant longtemps ?
Pourquoi certaines pages web peuvent-elles ne pas être indexées pendant longtemps ?
Il arrive que des pages web restent longtemps non indexées pour diverses raisons, généralement dues à une combinaison de facteurs. Les moteurs de recherche comme Google ou Yandex ne sont pas tenus d'indexer toutes les pages qu'ils trouvent ; ils sélectionnent uniquement les URL qu'ils jugent pertinentes et de qualité.
L'une des causes les plus fréquentes est la faiblesse du maillage interne. Si une page n'est pas référencée par d'autres sections du site, il est plus difficile pour les moteurs de recherche de la découvrir et d'en comprendre l'importance. Ces pages restent souvent inactives, sans aucun impact sur le référencement, et peuvent être ignorées pendant de longues périodes.
Le deuxième facteur important est le budget d'exploration. Chaque site web dispose de ressources limitées que les moteurs de recherche sont prêts à consacrer à son exploration. Si un site comporte des milliers, voire des millions d'URL (par exemple, des filtres, des paramètres ou des doublons), le robot d'exploration risque de perdre du temps sur des pages moins importantes, et de passer à côté de celles dont il a besoin. Par conséquent, certaines URL sont soit retardées, soit complètement ignorées.
Les erreurs techniques constituent une autre cause fréquente. Si une page renvoie une réponse instable du serveur, met longtemps à charger, contient des erreurs HTML ou des directives contradictoires (par exemple, une URL canonique pointe vers une autre URL pendant que la page est ouverte pour l'indexation), le moteur de recherche peut retarder ou annuler son indexation. Les restrictions du fichier robots.txt ou la balise méta noindex ont un effet similaire.
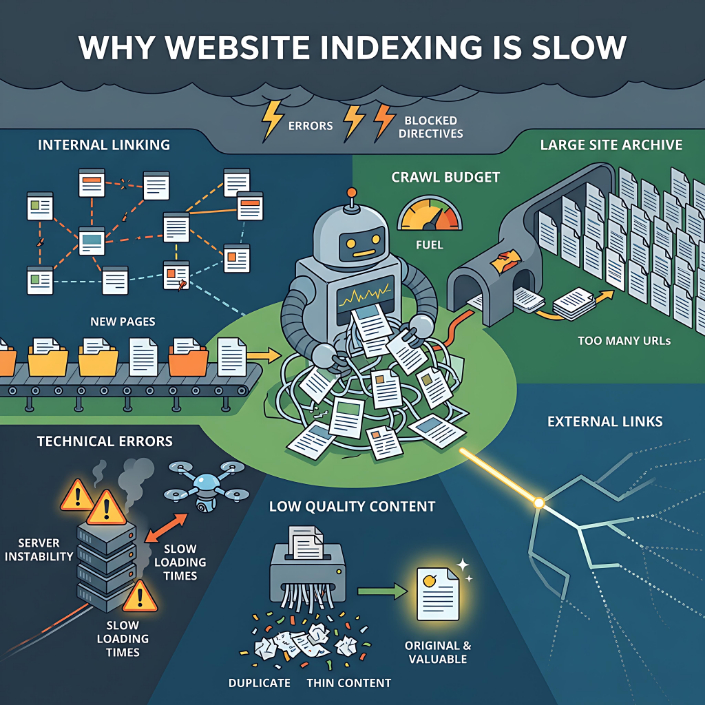
La qualité du contenu mérite une attention particulière. Même si une page est accessible et techniquement correcte, elle peut ne pas être indexée si le moteur de recherche la juge peu pertinente. Cela concerne les pages dupliquées, le contenu généré automatiquement, les pages au contenu pauvre en informations ou les pages produits génériques sans description unique. Dans ces cas-là, le moteur de recherche peut explorer la page sans pour autant l'inclure dans son index.
Les signaux externes sont également importants. Si une page ne comporte aucun lien externe et n'est mentionnée en dehors du site, ses chances d'être indexée rapidement diminuent. Les moteurs de recherche utilisent les liens comme un signal clé pour détecter et évaluer l'importance des pages.
Les problèmes d'indexation sont particulièrement fréquents sur les sites web à la structure complexe, tels que les boutiques en ligne, les catalogues, les agrégateurs et les sites d'actualités. Ces sites comportent de nombreuses pages similaires, des filtres, des URL variables et du contenu dynamique, ce qui surcharge les robots d'exploration et augmente le risque de doublons. Les sites web récents rencontrent une situation similaire : n'ayant pas encore établi de relation de confiance avec les moteurs de recherche, leur indexation peut être plus lente.
De plus, l'ajout simultané d'un grand nombre de nouvelles URL peut également ralentir le processus. Les moteurs de recherche ne traitent pas toujours tout en même temps ; ils répartissent les ressources progressivement, surtout si le site n'a pas démontré auparavant une qualité constante.
En définitive, une indexation lente indique que le moteur de recherche a des difficultés à accéder à la page ou qu'il ne la juge pas suffisamment pertinente. Par conséquent, une stratégie efficace ne consiste pas simplement à « pousser » les URL à l'indexation, mais aussi à optimiser simultanément la qualité du contenu, la structure du site, le maillage interne et l'état technique.










