- Principal
- FAQ
- Autres questions
- Quel est l'impact de l'utilisation d'un fichier robots.txt sur l'indexation par Google ?
Quel est l'impact de l'utilisation d'un fichier robots.txt sur l'indexation par Google ?
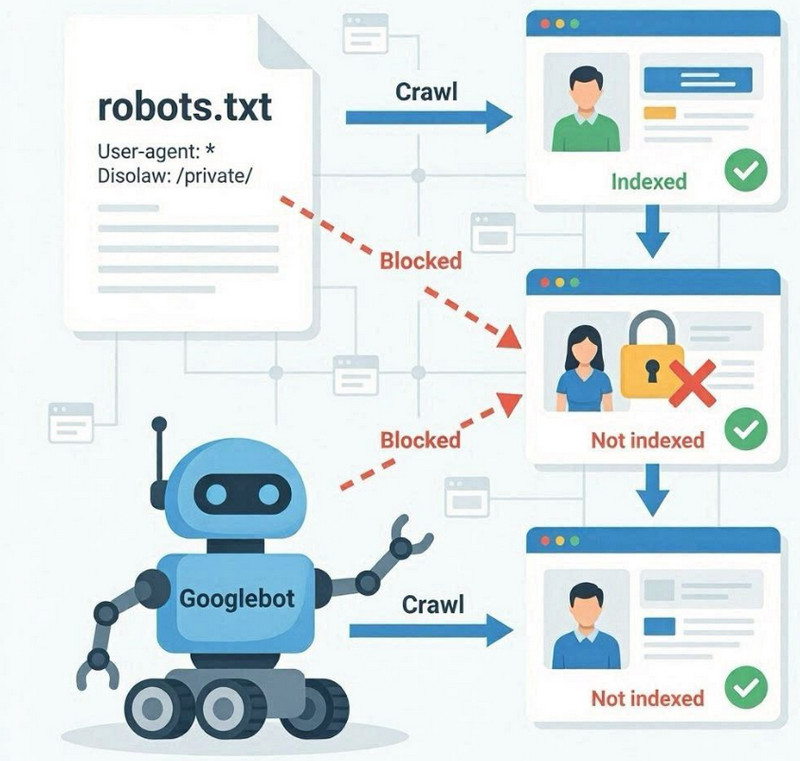
Le fichier robots.txt est un fichier technique situé à la racine d'un site web qui définit les règles destinées aux robots des moteurs de recherche concernant les sections à explorer et celles à ignorer. Sa fonction principale est de contrôler l'exploration, et non d'indexer directement les pages.
Lorsque Googlebot accède à un site web, il consulte d'abord le fichier robots.txt. Si ce dernier spécifie des restrictions via la directive Disallow , le robot ne pourra pas accéder à certaines sections ou URL. Par conséquent, ces pages ne seront pas explorées et leur contenu ne sera pas entièrement traité pour l'indexation.
La différence entre l'exploration et l'indexation
Le fichier robots.txt n'empêche pas directement l'indexation. Il restreint l'accès des robots d'exploration. Il s'agit d'une distinction importante : une page peut être connue de Google via des liens externes ou des mentions internes, mais ne pourra pas être explorée si l'accès lui est refusé.
Dans de tels cas, Google peut conserver l'URL dans l'index sans analyser pleinement le contenu, ce qui conduit à une interprétation limitée ou incorrecte de la page dans les résultats de recherche.
Risques liés à une configuration incorrecte
Les erreurs dans le fichier robots.txt peuvent nuire considérablement à la visibilité d'un site web. Si des sections importantes, comme les catégories, les pages produits ou les articles, sont omises par inadvertance, les moteurs de recherche ne pourront pas les explorer. Par conséquent, ces pages seront absentes de l'index ou partiellement indexées.
Le blocage des ressources (CSS, JavaScript) constitue également une erreur critique, car il empêche l'affichage correct de la page. Cela peut entraîner une mauvaise évaluation de la qualité et de la structure du contenu par Google.
Utilisation du fichier robots.txt pour optimiser l'exploration du Web
Correctement configuré, ce fichier permet d'allouer efficacement le budget d'exploration. La désactivation des pages de service, des filtres, des paramètres d'URL et des doublons permet au moteur de recherche de se concentrer sur les pages les plus importantes du site.
Ceci est particulièrement important pour les grands sites où le nombre de pages peut se chiffrer en milliers, voire en millions, et où un moteur de recherche ne peut physiquement pas toutes les explorer en une seule itération.
Ainsi, le fichier robots.txt influence l'indexation en contrôlant l'accès aux robots d'exploration : il détermine quelles pages Google peut examiner, et donc lesquelles seront potentiellement indexées et incluses dans les résultats de recherche.










