- Principale
- FAQ
- Altre domande
- In che modo l'utilizzo di un file robots.txt influisce sull'indicizzazione di Google?
In che modo l'utilizzo di un file robots.txt influisce sull'indicizzazione di Google?
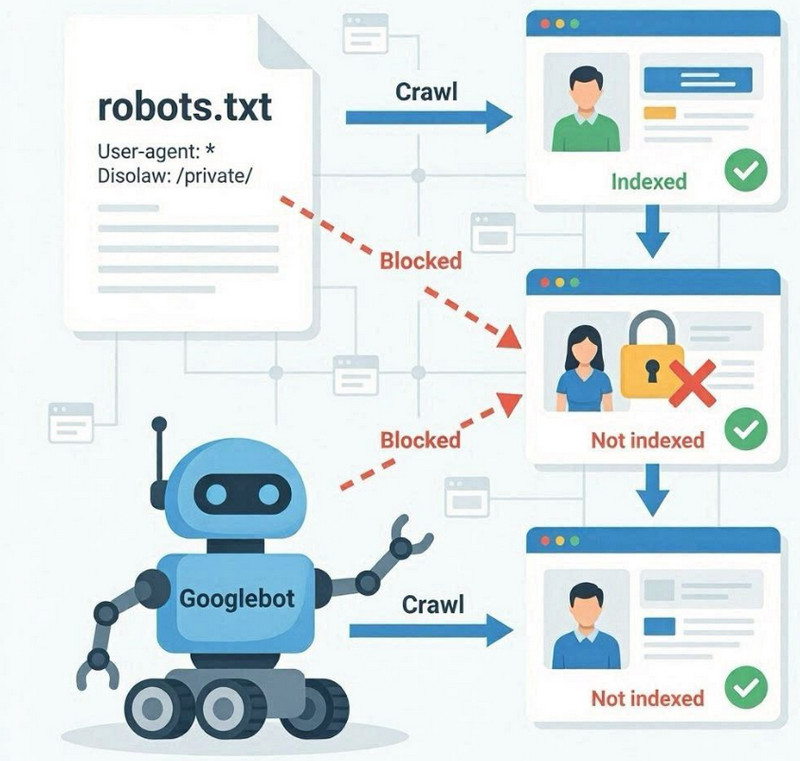
Il file robots.txt è un file tecnico presente nella directory principale di un sito web che definisce le regole per i bot dei motori di ricerca riguardo alle sezioni che possono essere scansionate e a quelle che devono essere ignorate. La sua funzione principale è quella di controllare la scansione, non di indicizzare direttamente le pagine.
Quando Googlebot accede a un sito web, controlla innanzitutto il file robots.txt. Se questo specifica delle restrizioni tramite la direttiva Disallow , il robot potrebbe non accedere a determinate sezioni o URL. Ciò significa che tali pagine non verranno scansionate e, di conseguenza, il loro contenuto non verrà elaborato completamente per l'indicizzazione.
La differenza tra crawling e indicizzazione
Il file Robots.txt non impedisce direttamente l'indicizzazione, bensì limita l'accesso alla scansione. Questa è una distinzione importante: una pagina può essere nota a Google tramite link esterni o menzioni interne, ma non essere scansionata se l'accesso viene negato.
In questi casi, Google potrebbe mantenere l'URL nel suo indice senza analizzare completamente il contenuto, il che porta a un'interpretazione limitata o errata della pagina nei risultati di ricerca.
Rischi di una configurazione errata
Gli errori nel file robots.txt possono influire significativamente sulla visibilità di un sito web. Se sezioni importanti, come categorie, pagine di prodotto o articoli, vengono omesse accidentalmente, i motori di ricerca non saranno in grado di indicizzarle. Di conseguenza, queste pagine non saranno presenti nell'indice o saranno indicizzate solo parzialmente.
Anche il blocco delle risorse (CSS, JavaScript) è un errore critico, poiché impedisce il corretto rendering della pagina. Ciò può comportare una valutazione negativa da parte di Google in merito alla qualità e alla struttura dei contenuti.
Utilizzo di robots.txt per ottimizzare la scansione
Se configurato correttamente, questo file aiuta ad allocare in modo efficiente il budget di scansione. Disabilitando pagine di servizio, filtri, parametri URL e duplicati, il motore di ricerca può concentrarsi sulle pagine più importanti del sito.
Ciò è particolarmente importante per i siti di grandi dimensioni, dove il numero di pagine può arrivare a migliaia o milioni, e un motore di ricerca non è fisicamente in grado di indicizzarle tutte in un singolo ciclo.
Pertanto, il file robots.txt influenza l'indicizzazione controllando l'accesso dei motori di ricerca: determina quali pagine Google può esaminare e, di conseguenza, quali di esse saranno potenzialmente indicizzate e incluse nei risultati di ricerca.










