- Principal
- Preguntas frecuentes
- Otras preguntas
- ¿Cómo afecta el uso de un archivo robots.txt a la indexación de Google?
¿Cómo afecta el uso de un archivo robots.txt a la indexación de Google?
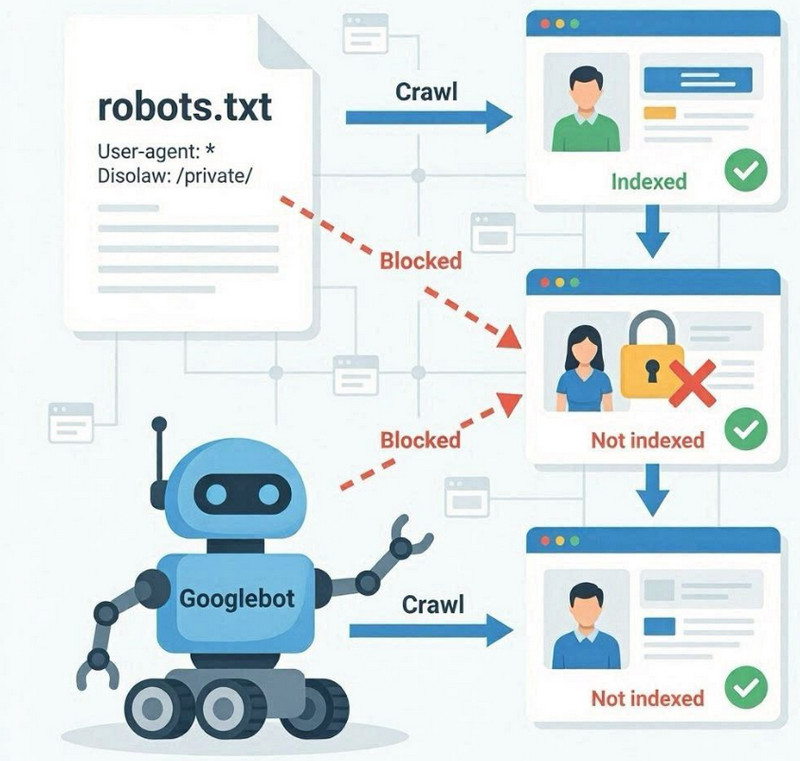
El archivo robots.txt es un archivo técnico ubicado en la raíz de un sitio web que establece reglas para los bots de los motores de búsqueda sobre qué secciones pueden ser rastreadas y cuáles deben ser ignoradas. Su función principal es controlar el rastreo, no indexar directamente las páginas.
Cuando Googlebot accede a un sitio web, primero revisa el archivo robots.txt. Si este especifica restricciones mediante la directiva Disallow , el robot podría no acceder a ciertas secciones o URL. Esto significa que dichas páginas no serán rastreadas y, por lo tanto, su contenido no se procesará completamente para su indexación.
La diferencia entre rastreo e indexación
El archivo robots.txt no impide directamente la indexación, sino que restringe el acceso de rastreo. Esta es una distinción importante: una página puede ser conocida por Google a través de enlaces externos o menciones internas, pero aun así no podrá ser rastreada si se deniega el acceso.
En estos casos, Google puede mantener la URL en su índice sin analizar completamente el contenido, lo que conlleva una interpretación limitada o incorrecta de la página en los resultados de búsqueda.
Riesgos de una configuración incorrecta
Los errores en el archivo robots.txt pueden afectar significativamente la visibilidad de un sitio web. Si se omiten accidentalmente secciones importantes, como categorías, páginas de productos o artículos, los motores de búsqueda no podrán indexarlas. Esto provoca que estas páginas no aparezcan en el índice o que su indexación sea incompleta.
Bloquear recursos (CSS, JavaScript) también es un error crítico, ya que impide que la página se visualice correctamente. Esto puede provocar que Google evalúe negativamente la calidad y la estructura del contenido.
Utilizar robots.txt para optimizar el rastreo
Cuando se configura correctamente, este archivo ayuda a asignar de manera eficiente el presupuesto de rastreo. Deshabilitar las páginas de servicio, los filtros, los parámetros de URL y los duplicados permite que el motor de búsqueda se centre en las páginas más importantes del sitio.
Esto es especialmente importante para sitios web grandes, donde el número de páginas puede ser de miles o millones, y un motor de búsqueda físicamente no puede rastrearlas todas en un solo ciclo.
De este modo, el archivo robots.txt influye en la indexación al controlar el acceso de rastreo: determina qué páginas puede examinar Google y, por lo tanto, cuáles de ellas serán potencialmente indexadas e incluidas en los resultados de búsqueda.










