- Главная
- Вопрос / Ответ
- Другие вопросы
- Каким образом использование файла robots.txt влияет на индексацию в Google?
Каким образом использование файла robots.txt влияет на индексацию в Google?
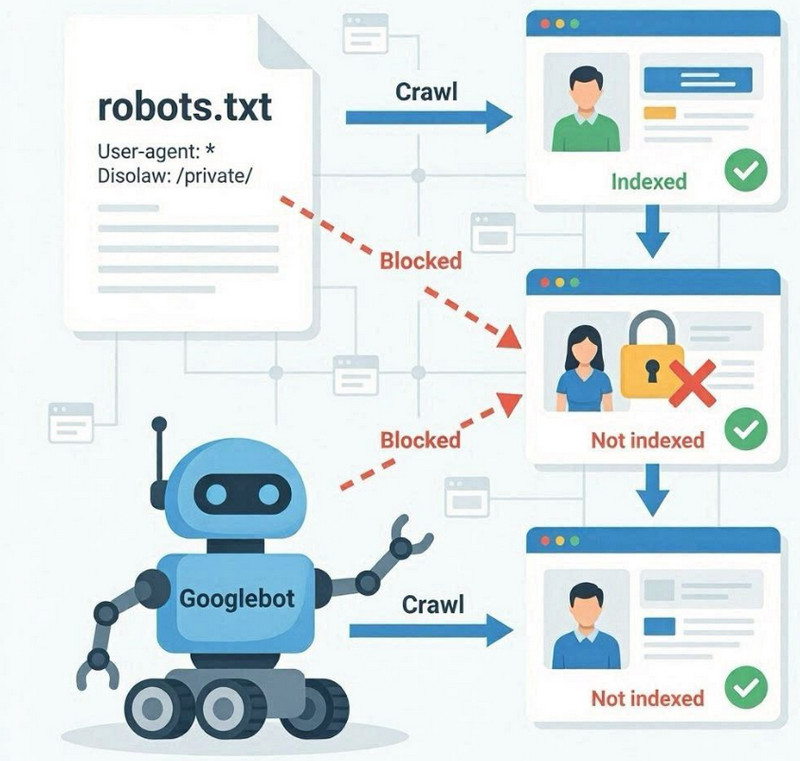
Файл robots.txt — это технический файл в корне сайта, который задаёт правила для поисковых роботов о том, какие разделы можно сканировать, а какие следует игнорировать. Его ключевая функция связана именно с управлением краулингом, а не с прямой индексацией страниц.
Когда Googlebot обращается к сайту, он в первую очередь проверяет robots.txt. Если в нём указаны ограничения через директиву Disallow, робот может не заходить в определённые разделы или URL. Это означает, что такие страницы не будут просканированы, а значит их содержимое не будет полноценно обработано для включения в индекс.
Разница между сканированием и индексацией
robots.txt не запрещает индексацию напрямую. Он ограничивает доступ к сканированию. Это важное различие: страница может быть известна Google через внешние ссылки или внутренние упоминания, но при этом не сканироваться, если доступ закрыт.
В таких случаях Google может сохранить URL в индексе без полноценного анализа контента, что приводит к ограниченной или некорректной интерпретации страницы в поиске.
Риски неправильной настройки
Ошибки в robots.txt могут существенно повлиять на видимость сайта. Если случайно закрыть важные разделы, например категории, карточки товаров или статьи, поисковый робот не сможет их обойти. Это приводит к отсутствию этих страниц в индексе или к их неполному пониманию системой.
Также критичной ошибкой является блокировка ресурсов (CSS, JavaScript), так как это мешает корректному рендерингу страницы. В результате Google может хуже оценивать качество и структуру контента.
Использование robots.txt для оптимизации обхода
При правильной настройке файл помогает эффективно распределять краулинговый бюджет. Закрытие служебных страниц, фильтров, параметров URL и дублей позволяет поисковому роботу сосредоточиться на важных страницах сайта.
Это особенно важно для больших сайтов, где количество страниц может исчисляться тысячами или миллионами, и поисковая система физически не может обойти всё за один цикл.
Таким образом, robots.txt влияет на индексацию через управление доступом к сканированию: он определяет, какие страницы Google сможет изучить, а значит — какие из них потенциально попадут в индекс и будут участвовать в поисковой выдаче.










