- Головна
- Питання / Відповідь
- Інші питання
- Яким чином використання файлу robots.txt впливає на індексацію в Google?
Яким чином використання файлу robots.txt впливає на індексацію в Google?
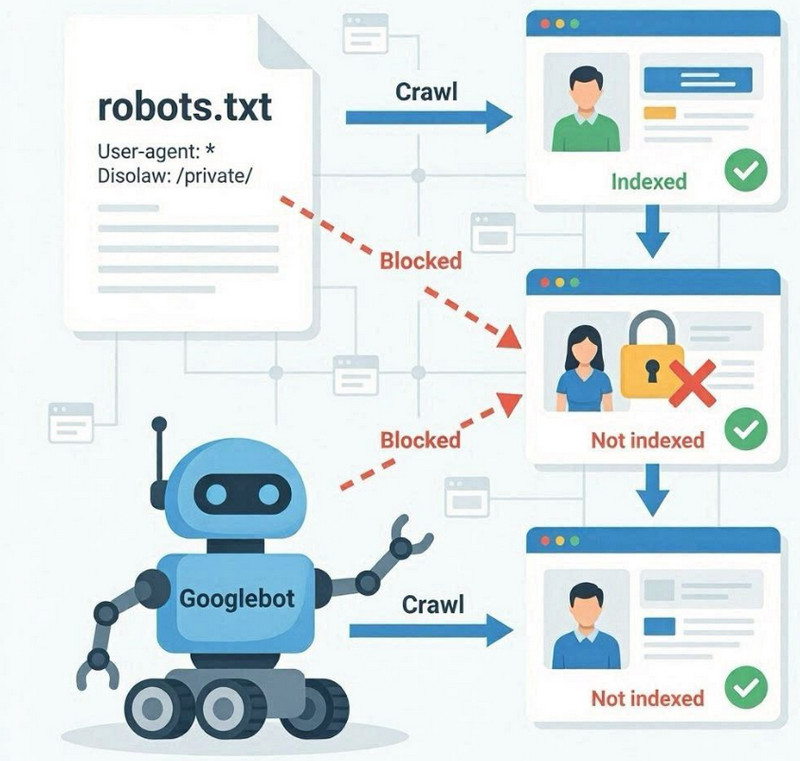
Файл robots.txt – це технічний файл у корені сайту, який визначає правила для пошукових роботів про те, які розділи можна сканувати, а які слід ігнорувати. Його ключова функція пов'язана саме з керуванням краулінгом, а не з прямою індексацією сторінок.
Коли Googlebot звертається до сайту, він спочатку перевіряє robots.txt. Якщо в ньому вказані обмеження через директиву Disallow , робот може не входити до певних розділів або URL-адрес. Це означає, що такі сторінки не будуть проскановані, а значить, їх вміст не буде повноцінно оброблений для включення до індексу.
Різниця між скануванням та індексацією
robots.txt не забороняє індексацію безпосередньо. Він обмежує доступ до сканування. Це важлива відмінність: сторінка може бути відома Google через зовнішні посилання або внутрішні згадки, але не скануватися, якщо доступ закритий.
У таких випадках Google може зберегти URL-адресу в індексі без повноцінного аналізу контенту, що призводить до обмеженої або некоректної інтерпретації сторінки в пошуку.
Ризики неправильного налаштування
Помилки в robots.txt можуть суттєво вплинути на видимість сайту. Якщо випадково закрити важливі розділи, наприклад, категорії, картки товарів чи статті, пошуковий робот не зможе їх обійти. Це призводить до відсутності цих сторінок в індексі або до їхнього неповного розуміння системою.
Також критичною помилкою є блокування ресурсів (CSS, JavaScript), оскільки це заважає коректному рендерингу сторінки. В результаті Google може гірше оцінювати якість та структуру контенту.
Використання robots.txt для оптимізації обходу
При правильному налаштуванні файл допомагає ефективно розподіляти краулінговий бюджет. Закриття службових сторінок, фільтрів, параметрів URL та дублів дозволяє пошуковому роботі зосередитися на важливих сторінках сайту.
Це особливо важливо для великих сайтів, де кількість сторінок може обчислюватись тисячами чи мільйонами, і пошукова система фізично не може обійти все за один цикл.
Таким чином, robots.txt впливає на індексацію через керування доступом до сканування: він визначає, які сторінки Google зможе вивчити, а отже, які з них потенційно потраплять до індексу та братимуть участь у пошуковій видачі.










