- Головна
- Питання / Відповідь
- Інші питання
- Як пошукова система знаходить нові сторінки сайту?
Як пошукова система знаходить нові сторінки сайту?
- Загальні питання щодо індексації
- Як працює 2index.ninja
- Індексація сторінок сайту
- Індексація зворотних посилань
- Перевірка індексації в Google
- Тарифи, токени та оплата
- API та масова робота
- Гарантії, терміни та результати
- Безпека та обмеження
- Технічні питання
-
Інші питання
- Як використовувати відстеження конкурентів у стратегії залучення беклінків?
- Який важливий контент при залученні беклінків?
- Як забезпечити хорошу швидкість завантаження сторінок для кращої індексації та оптимізації?
- Які рекомендації щодо оптимізації сторінок допоможуть покращити їх індексацію?
- Як перевірити, які сторінки були проіндексовані пошуковою системою?
- Як внутрішня перелінковка допомагає оптимізації для індексації Yandex?
- Як швидка індексація впливає на позиції результатів пошуку?
- Як моніторити якість зовнішніх посилань на свій сайт?
- Які методи можна використовувати для пошуку потенційних джерел беклінків?
- Які інструменти доступні для моніторингу беклінків?
- Як оцінити якість беклінків?
- Як оптимізація для швидкої швидкості завантаження сайту впливає на індексацію в Yandex?
- Яким чином використання файлу robots.txt впливає на індексацію в Google?
- Які специфічні рекомендації щодо оптимізації можна застосувати для кращої індексації в Yandex?
- Як оцінити доменний авторитет та сторінку авторитету іншого веб-ресурсу?
- Як перевірити, які сторінки мобільної версії вашого сайту індексує Google?
- Як вибрати ключові слова для конкретної сторінки?
- Як врахувати швидкість завантаження сторінок під час оптимізації для швидкої індексації?
- Як впливає довжина контенту на індексацію та ранжування сторінок?
- Які переваги сервісів індексування сторінок сайту?
- Що таке канонічний URL і як він використовується у SEO?
- Які основні кроки можуть покращити індексацію в Google?
- Як переконатися, що ваш сайт мобільно-дружелюбний для Google?
- Як створити та надіслати карту сайту (sitemap) для Google?
- Як пришвидшити процес індексації нових сторінок сайту?
- Як впливають соціальні сигнали на SEO?
- Як вибрати ключові слова для свого сайту?
- Які помилки слід уникати при залученні беклінків?
- Яким чином можна використовувати контент-маркетинг у стратегії залучення беклінків?
- Які метрики слід відстежувати в оцінці ефективності стратегії залучення бэклинков?
- Яка роль анкорних текстів у стратегії залучення беклінків?
- Які види беклінків існують?
- Які переваги несе залучення беклінків?
- Які ролі відіграють соціальні мережі у SEO?
- Що таке довгий хвіст ключових слів (long-tail keywords) і як вони використовуються у SEO?
- Який контент вважається якісним із погляду SEO?
- Як виміряти ефективність SEO та які метрики слід відстежувати?
- Що таке органічний пошук?
- Що таке Sitemap (мапа сайту) і як вона допомагає SEO?
- Що таке краулінг і як він пов'язаний із індексацією?
- Які інструменти для аналізу SEO можна використати?
- Що таке беклінки (зовнішні посилання) та як вони впливають на SEO?
- Які фактори впливають на швидкість завантаження сайту та чому це важливо для SEO?
- Що таке ключові слова (keywords) у SEO?
- Що таке мета-теги та як вони впливають на SEO?
- Що таке SEO (пошукова оптимізація)?
- Що таке Яндекс.Вебмайстер?
- Що таке Google Search Console?
- Що таке активне посилання?
- Як пошукова система знаходить нові сторінки сайту?
- Як перевірити результат
- Як довго відбувається індексація?
- Як це працює
- Скільки це обійдеться
- Чи будуть проіндексовані всі сторінки та посилання?
Пошукова система знаходить нові сторінки через процес, який називається краулінг (crawling) - обхід сайту роботами (павуками).
Обхід сайту роботами
У пошукових системах, таких як Google і Microsoft Bing, є автоматичні роботи (наприклад, Googlebot). Вони постійно сканують інтернет, переходячи за посиланнями з відомих сторінок на нові.
Якщо бот потрапляє на сторінку вашого сайту, він:
- завантажує HTML-код;
- аналізує контент;
- отримує посилання;
- додає нові URL у чергу обходу.
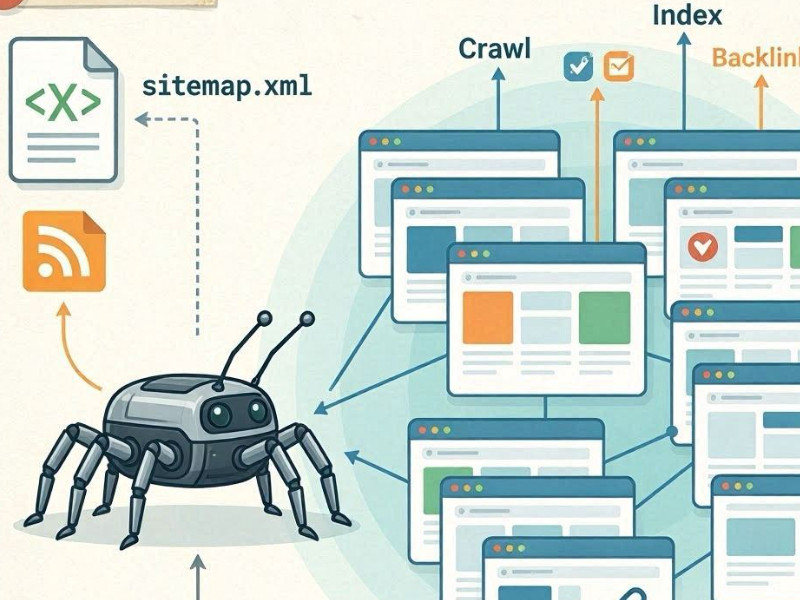
Внутрішні посилання як основний канал виявлення
Головний спосіб виявлення нових сторінок - це внутрішня перелінковка. Якщо нова сторінка:
- додано в меню,
- пов'язана з вже проіндексованою сторінкою,
- або присутній у каталозі,
- то бот швидше її знаходить і додає в обхід.
Sitemap.xml
Друге важливе джерело – файл sitemap.xml. Це мапа сайту, де ви явно перераховуєте всі важливі URL-адреси. Пошуковик використовує її як «план обходу», особливо для нових або глибоко вкладених сторінок.
Зовнішні сигнали
Якщо на сторінку ведуть зовнішні посилання з інших сайтів, блогів чи соцмереж, це прискорює її виявлення. Для пошукової системи це сигнал, що контент може бути новим і важливим.
Повторні обходи (re-crawling)
Пошукові системи регулярно повертаються на відомі сайти. Частота залежить від:
- авторитетності домену;
- частоти оновлення контенту;
- поведінки користувачів.
Чим "живіше" сайт, тим частіше бот перевіряє наявність нових сторінок.










