- मुख्य
- FAQ
- अन्य प्रश्न
- सर्च इंजन नई वेबसाइट पेज कैसे ढूंढता है?
सर्च इंजन नई वेबसाइट पेज कैसे ढूंढता है?
- अनुक्रमणिका के बारे में सामान्य प्रश्न
- 2index.ninja कैसे काम करता है
- वेबसाइट पेजों की इंडेक्सिंग
- बैकलिंक इंडेक्सिंग
- गूगल इंडेक्सिंग की जाँच की जा रही है
- शुल्क, टोकन और भुगतान
- एपीआई और बल्क वर्क
- गारंटी, समय सीमा और परिणाम
- सुरक्षा और प्रतिबंध
- तकनीकी प्रश्न
-
अन्य प्रश्न
- बैकलिंक अधिग्रहण रणनीति में प्रतिस्पर्धी ट्रैकिंग का उपयोग कैसे करें?
- बैकलिंक्स आकर्षित करने में कंटेंट कितना महत्वपूर्ण है?
- बेहतर इंडेक्सिंग और ऑप्टिमाइज़ेशन के लिए पेज लोडिंग स्पीड को कैसे सुनिश्चित किया जाए?
- पेज ऑप्टिमाइजेशन के कौन से सुझाव उनकी इंडेक्सिंग को बेहतर बनाने में मदद करेंगे?
- यह कैसे जांचें कि किसी सर्च इंजन द्वारा किन पेजों को इंडेक्स किया गया है?
- इंटरनल लिंकिंग, यांडेक्स इंडेक्सिंग को ऑप्टिमाइज़ करने में कैसे मदद करती है?
- तेज़ इंडेक्सिंग खोज परिणामों की स्थिति को कैसे प्रभावित करती है?
- आप अपनी साइट के बाहरी लिंक की गुणवत्ता की निगरानी कैसे कर सकते हैं?
- बैकलिंक के संभावित स्रोतों को खोजने के लिए किन तरीकों का उपयोग किया जा सकता है?
- बैकलिंक मॉनिटरिंग के लिए कौन-कौन से उपकरण उपलब्ध हैं?
- बैकलिंक्स की गुणवत्ता का मूल्यांकन कैसे करें?
- वेबसाइट की लोडिंग स्पीड को ऑप्टिमाइज़ करने से यांडेक्स में इंडेक्सिंग पर क्या असर पड़ता है?
- robots.txt फ़ाइल का उपयोग करने से Google इंडेक्सिंग पर क्या प्रभाव पड़ता है?
- यांडेक्स में बेहतर इंडेक्सिंग के लिए कौन-कौन से विशिष्ट ऑप्टिमाइजेशन सुझाव लागू किए जा सकते हैं?
- किसी अन्य वेब संसाधन की डोमेन अथॉरिटी और पेज अथॉरिटी का मूल्यांकन कैसे करें?
- आप यह कैसे जांच सकते हैं कि आपकी मोबाइल साइट के कौन से पेज गूगल द्वारा इंडेक्स किए गए हैं?
- किसी विशिष्ट पेज के लिए सही कीवर्ड कैसे चुनें?
- तेज़ इंडेक्सिंग के लिए ऑप्टिमाइज़ करते समय आप पेज लोडिंग स्पीड को कैसे ध्यान में रखते हैं?
- सामग्री की लंबाई पेज इंडेक्सिंग और रैंकिंग को कैसे प्रभावित करती है?
- वेबसाइट पेज इंडेक्सिंग सेवाओं के क्या फायदे हैं?
- कैननिकल यूआरएल क्या है और एसईओ में इसका उपयोग कैसे किया जाता है?
- गूगल इंडेक्सिंग को बेहतर बनाने के बुनियादी चरण क्या हैं?
- आप यह कैसे सुनिश्चित कर सकते हैं कि आपकी वेबसाइट Google के लिए मोबाइल-फ्रेंडली है?
- Google को साइटमैप कैसे बनाएं और सबमिट करें?
- नई वेबसाइट पेजों की इंडेक्सिंग प्रक्रिया को कैसे तेज किया जाए?
- सोशल सिग्नल एसईओ को कैसे प्रभावित करते हैं?
- अपनी वेबसाइट के लिए सही कीवर्ड कैसे चुनें?
- बैकलिंक्स आकर्षित करते समय आपको किन गलतियों से बचना चाहिए?
- बैकलिंक अधिग्रहण रणनीति में कंटेंट मार्केटिंग का उपयोग कैसे किया जा सकता है?
- अपनी बैकलिंक अधिग्रहण रणनीति की प्रभावशीलता का मूल्यांकन करते समय आपको किन मापदंडों पर नज़र रखनी चाहिए?
- बैकलिंक अधिग्रहण रणनीति में एंकर टेक्स्ट की क्या भूमिका है?
- बैकलिंक कितने प्रकार के होते हैं?
- बैकलिंक्स आकर्षित करने के क्या फायदे हैं?
- एसईओ में सोशल मीडिया की क्या भूमिका होती है?
- लॉन्ग-टेल कीवर्ड क्या होते हैं और SEO में इनका उपयोग कैसे किया जाता है?
- एसईओ के दृष्टिकोण से किस प्रकार की सामग्री को गुणवत्तापूर्ण माना जाता है?
- एसईओ की प्रभावशीलता को कैसे मापा जाए और आपको किन मापदंडों पर नज़र रखनी चाहिए?
- ऑर्गेनिक सर्च क्या है?
- साइटमैप क्या है और यह एसईओ में कैसे मदद करता है?
- क्रॉलिंग क्या है और इसका इंडेक्सिंग से क्या संबंध है?
- एसईओ विश्लेषण के लिए किन उपकरणों का उपयोग किया जा सकता है?
- बैकलिंक्स (बाहरी लिंक) क्या होते हैं और वे एसईओ को कैसे प्रभावित करते हैं?
- वेबसाइट की लोडिंग स्पीड को कौन से कारक प्रभावित करते हैं और SEO के लिए यह क्यों महत्वपूर्ण है?
- एसईओ में कीवर्ड क्या होते हैं?
- मेटा टैग क्या होते हैं और वे एसईओ को कैसे प्रभावित करते हैं?
- एसईओ (सर्च इंजन ऑप्टिमाइजेशन) क्या है?
- Yandex.Webmaster क्या है?
- गूगल सर्च कंसोल क्या है?
- एक्टिव लिंक क्या होता है?
- सर्च इंजन नई वेबसाइट पेज कैसे ढूंढता है?
- परिणाम की जाँच कैसे करें
- इंडेक्सिंग में कितना समय लगता है?
- कैसे यह काम करता है
- इसका कितना मूल्य होगा?
- क्या सभी पेज और लिंक इंडेक्स किए जाएंगे?
एक सर्च इंजन क्रॉलिंग नामक प्रक्रिया के माध्यम से नए पेज ढूंढता है, जो रोबोट (स्पाइडर) का उपयोग करके किसी वेबसाइट को क्रॉल करने की प्रक्रिया है।
रोबोटों द्वारा वेबसाइट क्रॉलिंग
गूगल और माइक्रोसॉफ्ट बिंग जैसे सर्च इंजन स्वचालित बॉट (जैसे गूगलबॉट) का उपयोग करते हैं। ये बॉट लगातार इंटरनेट को स्कैन करते हैं और ज्ञात पेजों से नए पेजों तक लिंक का अनुसरण करते हैं।
यदि कोई बॉट आपकी वेबसाइट के किसी पेज पर आता है, तो वह:
- एचटीएमएल कोड लोड करता है;
- विषयवस्तु का विश्लेषण करता है;
- लिंक निकालता है;
- क्रॉल क्यू में नए यूआरएल जोड़ता है।
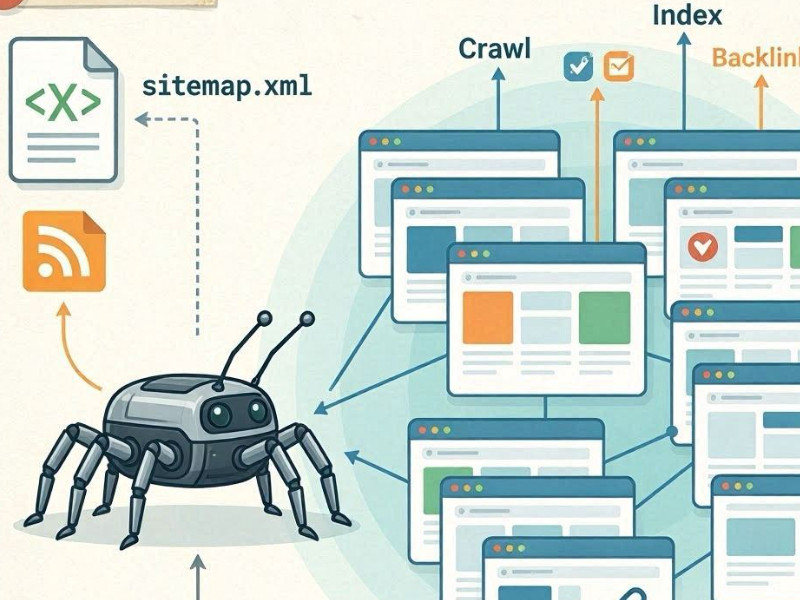
आंतरिक लिंक मुख्य खोज चैनल के रूप में
नए पेज खोजने का मुख्य तरीका आंतरिक लिंकिंग है। यदि कोई नया पेज:
- मेनू में जोड़ा गया,
- पहले से अनुक्रमित पृष्ठ से जुड़ा हुआ,
- या सूची में मौजूद है,
- फिर बॉट इसे तेजी से ढूंढ लेता है और इसे बाईपास में जोड़ देता है।
Sitemap.xml
दूसरा महत्वपूर्ण स्रोत sitemap.xml फ़ाइल है। यह एक साइटमैप है जिसमें आप सभी महत्वपूर्ण URL को स्पष्ट रूप से सूचीबद्ध करते हैं। सर्च इंजन इसका उपयोग "क्रॉल प्लान" के रूप में करते हैं, विशेष रूप से नए या गहराई से नेस्टेड पेजों के लिए।
बाह्य संकेत
यदि किसी पेज पर अन्य वेबसाइटों, ब्लॉगों या सोशल मीडिया से बाहरी लिंक हैं, तो इससे उसकी खोज में तेजी आती है। सर्च इंजन के लिए, यह एक संकेत है कि सामग्री नई और महत्वपूर्ण हो सकती है।
फिर से रेंगने
सर्च इंजन नियमित रूप से पहले से ज्ञात साइटों पर वापस आते हैं। इसकी आवृत्ति निम्नलिखित कारकों पर निर्भर करती है:
- डोमेन प्राधिकरण;
- सामग्री अद्यतन आवृत्ति;
- उपयोगकर्ता व्यवहार।
साइट जितनी अधिक सक्रिय होगी, बॉट उतनी ही अधिक बार नए पेजों की जांच करेगा।










