- Hauptseite
- FAQ
- Weitere Fragen
- Wie findet eine Suchmaschine neue Webseiten?
Wie findet eine Suchmaschine neue Webseiten?
- Allgemeine Fragen zur Indexierung
- So funktioniert 2index.ninja
- Indizierung von Webseiten
- Backlink-Indexierung
- Überprüfung der Google-Indexierung
- Tarife, Wertmarken und Zahlung
- API- und Massenverarbeitung
- Garantien, Fristen und Ergebnisse
- Sicherheit und Beschränkungen
- Technische Fragen
-
Weitere Fragen
- Wie kann man die Wettbewerbsbeobachtung in seine Backlink-Akquise-Strategie einbeziehen?
- Wie wichtig ist Content für den Aufbau von Backlinks?
- Wie lässt sich eine gute Seitenladegeschwindigkeit für eine bessere Indexierung und Optimierung sicherstellen?
- Welche Empfehlungen zur Seitenoptimierung tragen zur Verbesserung der Indexierung bei?
- Wie kann man überprüfen, welche Seiten von einer Suchmaschine indexiert wurden?
- Wie trägt interne Verlinkung zur Optimierung der Yandex-Indexierung bei?
- Wie wirkt sich eine schnelle Indexierung auf die Positionen der Suchergebnisse aus?
- Wie können Sie die Qualität externer Links zu Ihrer Website überwachen?
- Welche Methoden können verwendet werden, um potenzielle Backlink-Quellen zu finden?
- Welche Tools stehen für das Backlink-Monitoring zur Verfügung?
- Wie lässt sich die Qualität von Backlinks beurteilen?
- Wie wirkt sich die Optimierung der Website-Ladezeit auf die Indexierung bei Yandex aus?
- Wie wirkt sich die Verwendung einer robots.txt-Datei auf die Google-Indexierung aus?
- Welche konkreten Optimierungsempfehlungen können für eine bessere Indexierung in Yandex angewendet werden?
- Wie lässt sich die Domain- und Seitenautorität einer anderen Webressource bewerten?
- Wie kann man überprüfen, welche Seiten der eigenen mobilen Website von Google indexiert werden?
- Wie wählt man die richtigen Keywords für eine bestimmte Seite aus?
- Wie berücksichtigt man die Seitenladegeschwindigkeit bei der Optimierung für eine schnelle Indizierung?
- Wie beeinflusst die Inhaltslänge die Seitenindexierung und das Ranking?
- Welche Vorteile bieten Dienste zur Indexierung von Webseiten?
- Was ist eine kanonische URL und wie wird sie im SEO eingesetzt?
- Welche grundlegenden Schritte sind nötig, um die Google-Indexierung zu verbessern?
- Wie stelle ich sicher, dass meine Website für Google auf Mobilgeräten optimiert ist?
- Wie erstelle und übermittle ich eine Sitemap an Google?
- Wie kann der Indexierungsprozess neuer Webseiten beschleunigt werden?
- Wie beeinflussen soziale Signale die Suchmaschinenoptimierung?
- Wie wählt man die richtigen Keywords für seine Website aus?
- Welche Fehler sollten Sie beim Aufbau von Backlinks vermeiden?
- Wie kann Content-Marketing in einer Backlink-Akquise-Strategie eingesetzt werden?
- Welche Kennzahlen sollten Sie verfolgen, um die Effektivität Ihrer Backlink-Akquise-Strategie zu bewerten?
- Welche Rolle spielen Ankertexte in der Backlink-Akquise-Strategie?
- Welche Arten von Backlinks gibt es?
- Welche Vorteile bietet das Gewinnen von Backlinks?
- Welche Rolle spielen soziale Medien im SEO?
- Was sind Long-Tail-Keywords und wie werden sie im SEO eingesetzt?
- Welche Inhalte gelten aus SEO-Sicht als qualitativ hochwertig?
- Wie lässt sich die Effektivität von SEO messen und welche Kennzahlen sollten Sie verfolgen?
- Was ist organische Suche?
- Was ist eine Sitemap und wie hilft sie bei der Suchmaschinenoptimierung?
- Was ist Crawling und in welchem Zusammenhang steht es mit der Indexierung?
- Welche SEO-Analyse-Tools können verwendet werden?
- Was sind Backlinks (externe Links) und wie beeinflussen sie die Suchmaschinenoptimierung?
- Welche Faktoren beeinflussen die Ladezeit von Websites und warum ist dies für die Suchmaschinenoptimierung wichtig?
- Was sind Keywords im SEO-Bereich?
- Was sind Meta-Tags und wie beeinflussen sie die Suchmaschinenoptimierung?
- Was ist SEO (Suchmaschinenoptimierung)?
- Was ist Yandex.Webmaster?
- Was ist die Google Search Console?
- Was ist ein aktiver Link?
- Wie findet eine Suchmaschine neue Webseiten?
- Wie man das Ergebnis überprüft
- Wie lange dauert die Indizierung?
- Wie funktioniert das
- Wie viel wird es kosten?
- Werden alle Seiten und Links indexiert?
Eine Suchmaschine findet neue Seiten durch einen Prozess namens Crawling. Dabei wird eine Website mithilfe von Robotern (Webcrawlern) durchsucht.
Webseiten-Crawling durch Roboter
Suchmaschinen wie Google und Microsoft Bing verwenden automatisierte Bots (wie beispielsweise Googlebot). Diese durchsuchen ständig das Internet und folgen Links von bekannten Seiten zu neuen.
Wenn ein Bot auf einer Seite Ihrer Website landet, passiert Folgendes:
- lädt HTML-Code;
- analysiert Inhalte;
- extrahiert Links;
- Fügt neue URLs zur Crawl-Warteschlange hinzu.
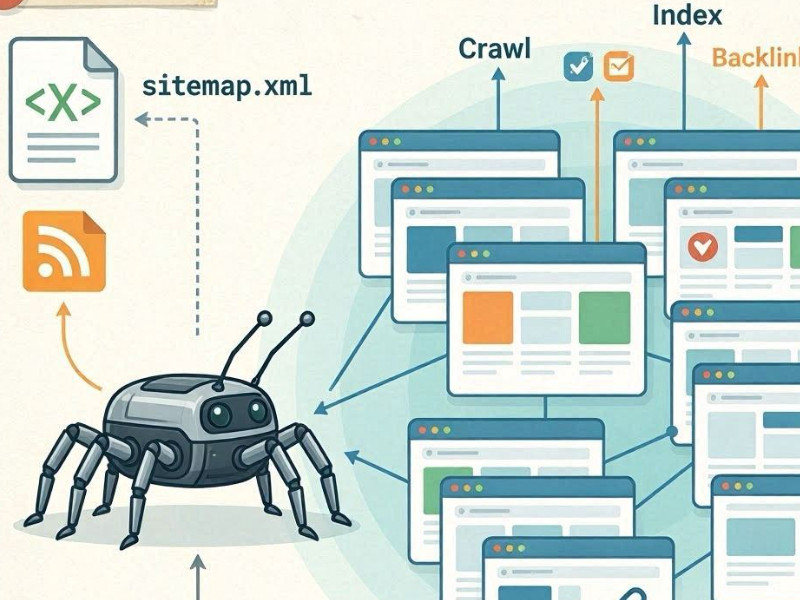
Interne Links als wichtigster Entdeckungskanal
Neue Seiten lassen sich hauptsächlich über interne Verlinkungen entdecken. Wenn eine neue Seite:
- wurde dem Menü hinzugefügt,
- verlinkt auf eine bereits indexierte Seite,
- oder im Katalog vorhanden ist,
- Dann findet der Bot es schneller und fügt es der Umgehungsliste hinzu.
Sitemap.xml
Die zweite wichtige Quelle ist die Sitemap.xml-Datei. Dies ist eine Sitemap, in der Sie alle wichtigen URLs explizit auflisten. Suchmaschinen verwenden sie als „Crawling-Plan“, insbesondere für neue oder tief verschachtelte Seiten.
Externe Signale
Wenn eine Seite externe Links von anderen Websites, Blogs oder sozialen Medien enthält, beschleunigt dies ihre Auffindbarkeit. Für Suchmaschinen ist dies ein Signal dafür, dass der Inhalt neu und wichtig sein könnte.
Wiederkriechen
Suchmaschinen kehren regelmäßig zu bereits bekannten Websites zurück. Die Häufigkeit hängt von folgenden Faktoren ab:
- Domänenautorität;
- Häufigkeit der Inhaltsaktualisierungen;
- Nutzerverhalten.
Je aktiver die Website ist, desto häufiger prüft der Bot, ob neue Seiten verfügbar sind.










