- Principale
- FAQ
- Altre domande
- Come fa un motore di ricerca a trovare nuove pagine web?
Come fa un motore di ricerca a trovare nuove pagine web?
- Domande generali sull'indicizzazione
- Come funziona 2index.ninja
- Indicizzazione delle pagine web
- Indicizzazione dei backlink
- Verifica dell'indicizzazione di Google
- Tariffe, gettoni e pagamenti
- API e lavoro in blocco
- Garanzie, scadenze e risultati
- Sicurezza e restrizioni
- Questioni tecniche
-
Altre domande
- Come utilizzare il monitoraggio della concorrenza nella propria strategia di acquisizione di backlink?
- Quanto è importante il contenuto per attrarre backlink?
- Come garantire una buona velocità di caricamento delle pagine per una migliore indicizzazione e ottimizzazione?
- Quali consigli di ottimizzazione della pagina possono contribuire a migliorarne l'indicizzazione?
- Come verificare quali pagine sono state indicizzate da un motore di ricerca?
- In che modo i link interni contribuiscono a ottimizzare l'indicizzazione di Yandex?
- In che modo l'indicizzazione rapida influisce sul posizionamento nei risultati di ricerca?
- Come si può monitorare la qualità dei link esterni al proprio sito?
- Quali metodi si possono utilizzare per individuare potenziali fonti di backlink?
- Quali strumenti sono disponibili per il monitoraggio dei backlink?
- Come valutare la qualità dei backlink?
- In che modo l'ottimizzazione per una rapida velocità di caricamento del sito web influisce sull'indicizzazione in Yandex?
- In che modo l'utilizzo di un file robots.txt influisce sull'indicizzazione di Google?
- Quali raccomandazioni specifiche di ottimizzazione si possono applicare per migliorare l'indicizzazione in Yandex?
- Come valutare l'autorevolezza del dominio e l'autorevolezza della pagina di un'altra risorsa web?
- Come si fa a verificare quali pagine del proprio sito mobile sono indicizzate da Google?
- Come scegliere le parole chiave giuste per una pagina specifica?
- Come si tiene conto della velocità di caricamento della pagina quando si ottimizza per un'indicizzazione rapida?
- In che modo la lunghezza del contenuto influisce sull'indicizzazione e sul posizionamento di una pagina?
- Quali sono i vantaggi dei servizi di indicizzazione delle pagine web?
- Che cos'è un URL canonico e come viene utilizzato nella SEO?
- Quali sono i passaggi fondamentali per migliorare l'indicizzazione su Google?
- Come assicurarsi che il proprio sito web sia ottimizzato per i dispositivi mobili da Google?
- Come creare e inviare una sitemap a Google?
- Come velocizzare il processo di indicizzazione delle nuove pagine web?
- In che modo i segnali social influenzano la SEO?
- Come scegliere le parole chiave giuste per il tuo sito web?
- Quali errori bisogna evitare quando si cercano di ottenere backlink?
- Come si può utilizzare il content marketing in una strategia di acquisizione di backlink?
- Quali metriche dovresti monitorare per valutare l'efficacia della tua strategia di acquisizione di backlink?
- Qual è il ruolo degli anchor text nella strategia di acquisizione di backlink?
- Che tipi di backlink esistono?
- Quali sono i vantaggi di attrarre backlink?
- Che ruolo svolgono i social media nella SEO?
- Cosa sono le parole chiave a coda lunga e come vengono utilizzate nella SEO?
- Quali contenuti sono considerati di qualità dal punto di vista della SEO?
- Come misurare l'efficacia della SEO e quali metriche monitorare?
- Che cos'è la ricerca organica?
- Cos'è una Sitemap e come contribuisce alla SEO?
- Cos'è la scansione (crawling) e qual è la sua relazione con l'indicizzazione?
- Quali strumenti di analisi SEO si possono utilizzare?
- Cosa sono i backlink (link esterni) e come influenzano la SEO?
- Quali fattori influenzano la velocità di caricamento di un sito web e perché è importante per la SEO?
- Cosa sono le parole chiave nella SEO?
- Cosa sono i meta tag e come influenzano la SEO?
- Cos'è la SEO (Ottimizzazione per i motori di ricerca)?
- Cos'è Yandex.Webmaster?
- Cos'è Google Search Console?
- Che cos'è un link attivo?
- Come fa un motore di ricerca a trovare nuove pagine web?
- Come verificare il risultato
- Quanto tempo richiede l'indicizzazione?
- Come funziona
- Quanto costa?
- Tutte le pagine e i link verranno indicizzati?
Un motore di ricerca trova nuove pagine attraverso un processo chiamato crawling, che consiste nella scansione di un sito web tramite robot (spider).
Scansione dei siti web da parte di robot
I motori di ricerca come Google e Microsoft Bing utilizzano bot automatizzati (come Googlebot). Questi bot scansionano costantemente Internet, seguendo i link dalle pagine conosciute a quelle nuove.
Se un bot atterra su una pagina del tuo sito web, esso:
- carica il codice HTML;
- analizza il contenuto;
- estrae i link;
- Aggiunge nuovi URL alla coda di scansione.
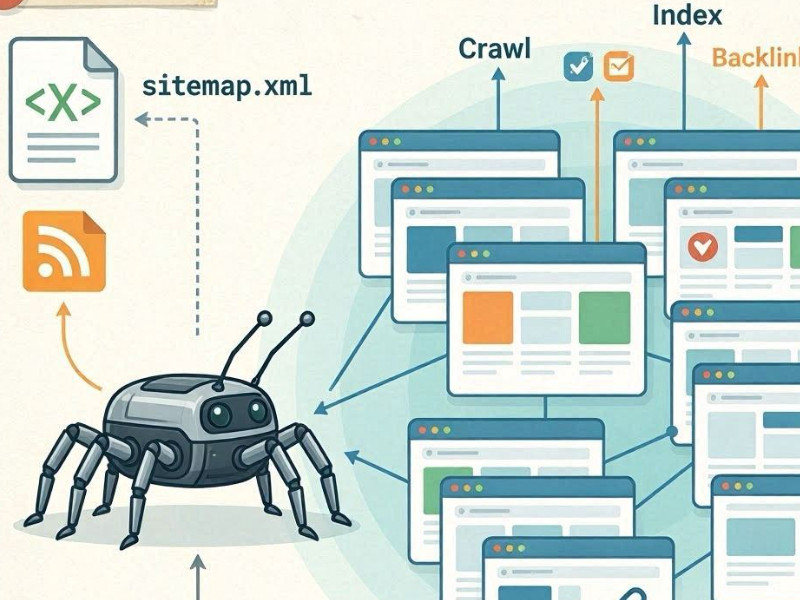
I link interni come principale canale di scoperta
Il modo principale per scoprire nuove pagine è attraverso i link interni. Se una nuova pagina:
- aggiunto al menu,
- collegato a una pagina già indicizzata,
- o è presente nel catalogo,
- in questo modo il bot lo trova più velocemente e lo aggiunge al percorso alternativo.
Sitemap.xml
La seconda fonte importante è il file sitemap.xml. Si tratta di una mappa del sito in cui vengono elencati esplicitamente tutti gli URL importanti. I motori di ricerca la utilizzano come "piano di scansione", soprattutto per le pagine nuove o quelle con una struttura di directory molto complessa.
segnali
Se una pagina contiene link esterni provenienti da altri siti web, blog o social media, la sua visibilità aumenta. Per i motori di ricerca, questo è un segnale che il contenuto potrebbe essere nuovo e importante.
Ri-scansionare
I motori di ricerca tornano regolarmente sui siti già noti. La frequenza dipende da:
- autorità di dominio;
- frequenza di aggiornamento dei contenuti;
- comportamento dell'utente.
Più il sito è attivo, più spesso il bot controlla la presenza di nuove pagine.










