- Главная
- Вопрос / Ответ
- Другие вопросы
- Как поисковая система находит новые страницы сайта?
Как поисковая система находит новые страницы сайта?
- Общие вопросы об индексации
- Как работает 2index.ninja
- Индексация страниц сайта
- Индексация обратных ссылок
- Проверка индексации в Google
- Тарифы, токены и оплата
- API и массовая работа
- Гарантии, сроки и результаты
- Безопасность и ограничения
- Технические вопросы
-
Другие вопросы
- Как использовать отслеживание конкурентов в стратегии привлечения бэклинков?
- Как важен контент при привлечении бэклинков?
- Как обеспечить хорошую скорость загрузки страниц для лучшей индексации и оптимизации?
- Какие рекомендации по оптимизации страниц помогут улучшить их индексацию?
- Как проверить, какие страницы были проиндексированы поисковой системой?
- Как внутренняя перелинковка помогает оптимизации для индексации в Yandex?
- Как быстрая индексация влияет на позиции в результатах поиска?
- Как можно мониторить качество внешних ссылок на свой сайт?
- Какие методы можно использовать для поиска потенциальных источников бэклинков?
- Какие инструменты доступны для мониторинга бэклинков?
- Как оценить качество бэклинков?
- Каким образом оптимизация для быстрой скорости загрузки сайта влияет на индексацию в Yandex?
- Каким образом использование файла robots.txt влияет на индексацию в Google?
- Какие специфические рекомендации по оптимизации можно применить для лучшей индексации в Yandex?
- Как оценить доменный авторитет и страницу авторитета другого веб-ресурса?
- Как проверить, какие страницы мобильной версии вашего сайта индексирует Google?
- Как выбрать правильные ключевые слова для конкретной страницы?
- Как учесть скорость загрузки страниц при оптимизации для быстрой индексации?
- Как влияет длина контента на индексацию и ранжирование страниц?
- Какие преимущества сервисов индексирования страниц сайта?
- Что такое канонический URL и как он используется в SEO?
- Какие основные шаги могут улучшить индексацию в Google?
- Как убедиться, что ваш сайт мобильно-дружелюбен для Google?
- Как создать и отправить карту сайта (sitemap) для Google?
- Как ускорить процесс индексации новых страниц сайта?
- Как влияют социальные сигналы на SEO?
- Как выбрать правильные ключевые слова для своего сайта?
- Какие ошибки следует избегать при привлечении бэклинков?
- Каким образом можно использовать контент-маркетинг в стратегии привлечения бэклинков?
- Какие метрики следует отслеживать при оценке эффективности стратегии привлечения бэклинков?
- Какова роль анкорных текстов в стратегии привлечения бэклинков?
- Какие виды бэклинков существуют?
- Какие преимущества несет привлечение бэклинков?
- Какие роли играют социальные сети в SEO?
- Что такое длинный хвост ключевых слов (long-tail keywords) и как они используются в SEO?
- Какой контент считается качественным с точки зрения SEO?
- Как измерить эффективность SEO и какие метрики следует отслеживать?
- Что такое органический поиск?
- Что такое Sitemap (карта сайта) и как она помогает SEO?
- Что такое краулинг и как он связан с индексацией?
- Какие инструменты для анализа SEO можно использовать?
- Что такое бэклинки (внешние ссылки) и как они влияют на SEO?
- Какие факторы влияют на скорость загрузки сайта и почему это важно для SEO?
- Что такое ключевые слова (keywords) в SEO?
- Что такое мета-теги и как они влияют на SEO?
- Что такое SEO (поисковая оптимизация)?
- Что такое Яндекс.Вебмастер?
- Что такое Google Search Console?
- Что такое активная ссылка?
- Как поисковая система находит новые страницы сайта?
- Как проверить результат
- Как долго происходит индексация?
- Как это работает
- Во сколько это обойдётся
- Будут ли проиндексированы все страницы и ссылки?
Поисковая система находит новые страницы через процесс, который называется краулинг (crawling) — обход сайта роботами (пауками).
Обход сайта роботами
У поисковых систем, таких как Google и Microsoft Bing, есть автоматические боты (например, Googlebot). Они постоянно сканируют интернет, переходя по ссылкам с уже известных страниц на новые.
Если бот попадает на страницу вашего сайта, он:
- загружает HTML-код;
- анализирует контент;
- извлекает ссылки;
- добавляет новые URL в очередь обхода.
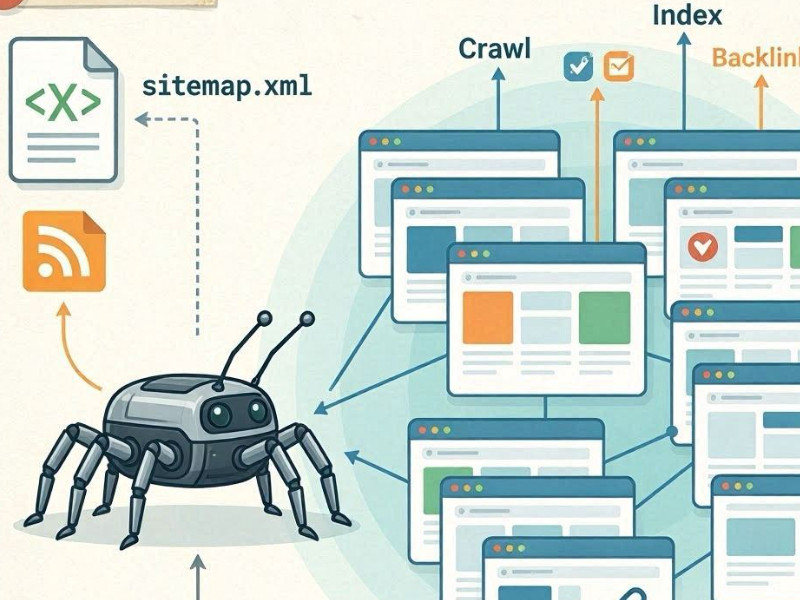
Внутренние ссылки как основной канал обнаружения
Главный способ обнаружения новых страниц — это внутренняя перелинковка. Если новая страница:
- добавлена в меню,
- связана с уже проиндексированной страницей,
- или присутствует в каталоге,
- то бот быстрее её находит и добавляет в обход.
Sitemap.xml
Второй важный источник — файл sitemap.xml. Это карта сайта, где вы явно перечисляете все важные URL. Поисковик использует её как «план обхода», особенно для новых или глубоко вложенных страниц.
Внешние сигналы
Если на страницу ведут внешние ссылки с других сайтов, блогов или соцсетей, это ускоряет её обнаружение. Для поисковика это сигнал, что контент может быть новым и важным.
Повторные обходы (re-crawling)
Поисковые системы регулярно возвращаются на уже известные сайты. Частота зависит от:
- авторитетности домена;
- частоты обновления контента;
- поведения пользователей.
Чем «живее» сайт, тем чаще бот проверяет наличие новых страниц.










