搜索引擎如何找到新的网页?
常见问题
- 关于索引的常见问题
- 2index.ninja 的工作原理
- 网站页面索引
- 反向链接索引
- 检查谷歌索引
- 关税、代币和支付
- API 和批量工作
- 保证、期限和结果
- 安全与限制
- 技术问题
-
其他问题
- 如何在反向链接获取策略中使用竞争对手跟踪?
- 内容在吸引反向链接方面有多重要?
- 如何确保良好的页面加载速度,从而实现更好的索引和优化?
- 哪些页面优化建议有助于提高它们的索引排名?
- 如何查看哪些页面已被搜索引擎收录?
- 内部链接如何帮助优化 Yandex 索引?
- 快速索引如何影响搜索结果排名?
- 如何监控指向您网站的外部链接的质量?
- 有哪些方法可以用来寻找潜在的反向链接来源?
- 有哪些工具可用于反向链接监控?
- 如何评估反向链接的质量?
- 优化网站加载速度对 Yandex 索引有何影响?
- 使用 robots.txt 文件会对 Google 索引产生什么影响?
- 为了提高Yandex的索引效果,可以采取哪些具体的优化建议?
- 如何评估其他网站资源的域名权威性和页面权威性?
- 如何查看您的移动网站哪些页面已被 Google 收录?
- 如何为特定页面选择合适的关键词?
- 在优化搜索引擎排名以实现快速索引时,如何考虑页面加载速度?
- 内容长度如何影响页面索引和排名?
- 网站页面索引服务有哪些好处?
- 什么是规范网址?它在搜索引擎优化(SEO)中是如何使用的?
- 提高谷歌索引质量的基本步骤有哪些?
- 如何确保您的网站对谷歌移动设备友好?
- 如何创建网站地图并提交给谷歌?
- 如何加快新网页的索引速度?
- 社交信号如何影响搜索引擎优化?
- 如何为你的网站选择合适的关键词?
- 在吸引反向链接时应该避免哪些错误?
- 如何将内容营销应用于反向链接获取策略?
- 评估反向链接获取策略的有效性时,应该跟踪哪些指标?
- 锚文本在反向链接获取策略中扮演什么角色?
- 反向链接有哪些类型?
- 吸引反向链接有什么好处?
- 社交媒体在搜索引擎优化(SEO)中扮演什么角色?
- 什么是长尾关键词?它们在搜索引擎优化(SEO)中是如何使用的?
- 从搜索引擎优化(SEO)的角度来看,什么样的内容才算优质内容?
- 如何衡量SEO效果?应该追踪哪些指标?
- 什么是自然搜索?
- 什么是网站地图?它如何帮助搜索引擎优化?
- 什么是网络爬虫?它与索引有什么关系?
- 可以使用哪些SEO分析工具?
- 什么是反向链接(外部链接)?它们如何影响搜索引擎优化(SEO)?
- 影响网站加载速度的因素有哪些?为什么网站加载速度对搜索引擎优化(SEO)很重要?
- SEO中的关键词是什么?
- 什么是元标签?它们如何影响搜索引擎优化?
- 什么是SEO(搜索引擎优化)?
- Yandex.Webmaster 是什么?
- 什么是 Google Search Console?
- 什么是有效链接?
- 搜索引擎如何找到新的网页?
- 如何查看结果
- 索引需要多长时间?
- 这是如何运作的
- 费用是多少?
- 所有页面和链接都会被索引吗?
搜索引擎通过一种称为爬取的过程来查找新页面——爬取是指使用机器人(蜘蛛)爬取网站的过程。
机器人抓取网站
像谷歌和微软必应这样的搜索引擎都拥有自动化机器人(例如Googlebot)。它们会不断扫描互联网,追踪已知页面上的链接,找到新的页面。
如果机器人访问了您网站的某个页面,它会:
- 加载HTML代码;
- 分析内容;
- 提取链接;
- 将新的 URL 添加到抓取队列中。
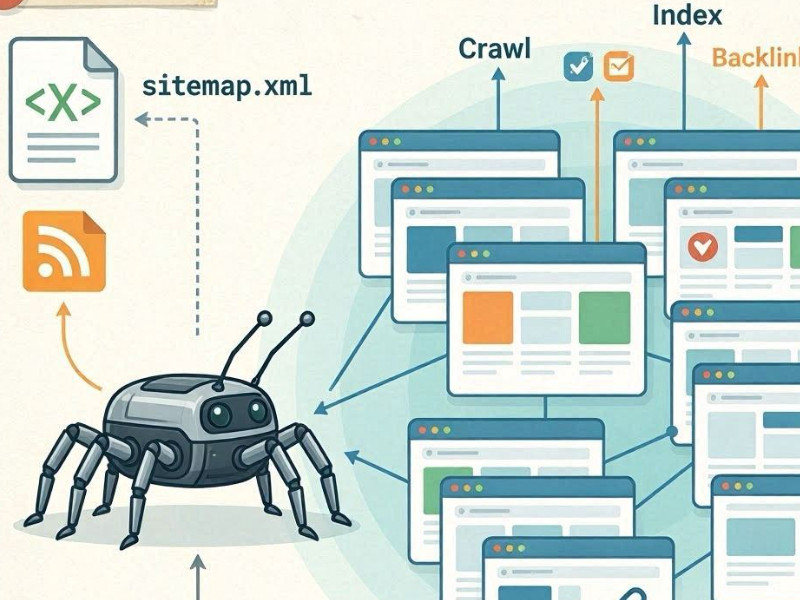
内部链接是主要发现渠道
发现新页面的主要方式是通过内部链接。如果一个新页面:
- 已添加到菜单中
- 链接到已索引的页面,
- 或者已收录于产品目录中,
- 然后机器人就能更快地找到它并将其添加到绕过列表中。
Sitemap.xml
第二个重要的资源是 sitemap.xml 文件。这是一个站点地图,您可以在其中明确列出所有重要的 URL。搜索引擎会将其用作“抓取计划”,尤其是在抓取新页面或嵌套较深的页面时。
外部信号
如果一个页面包含来自其他网站、博客或社交媒体的外部链接,就能加快其被发现的速度。对于搜索引擎而言,这表明该内容可能是新的且重要的。
重新爬行
搜索引擎会定期返回已收录的网站。返回频率取决于:
- 域名权重;
- 内容更新频率;
- 用户行为。
网站越活跃,机器人检查新页面的频率就越高。
如果您的问题仍未得到解答,您可以提交工单给我们。 我的工单










