- Hauptseite
- FAQ
- Garantien, Fristen und Ergebnisse
- Warum erkennt Google die Seite, indexiert sie aber nicht?
Warum erkennt Google die Seite, indexiert sie aber nicht?
Manchmal ist eine Seite zwar „auf Googles Radar“, wird aber nicht indexiert. Das ist normal und eines der häufigsten Szenarien in der modernen SEO-Praxis.
Es ist wichtig, zwischen drei Zuständen zu unterscheiden: URL-Erkennung, Crawling und Indexierung. In Fällen wie „Erkennt – derzeit nicht indexiert“ oder „Gecrawlt – derzeit nicht indexiert“ in der Google Search Console kennt Google die Seite bereits und hat sie möglicherweise sogar besucht, aber aus irgendeinem Grund noch nicht in den Index aufgenommen.
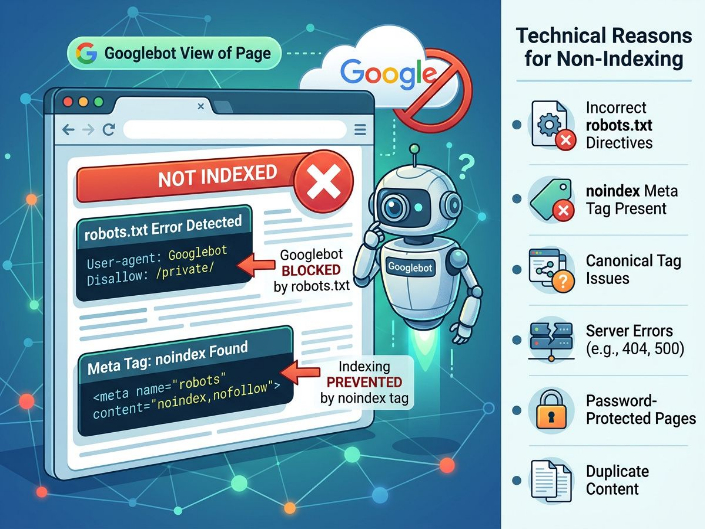
Der Hauptgrund für dieses Verhalten liegt in der Bewertung der Qualität und Priorität einer Seite. Selbst wenn eine URL technisch erreichbar ist, kann Google die Indexierung verzögern oder vollständig ablehnen, wenn die Seite im Vergleich zu bestehenden Suchergebnissen keinen ausreichenden Mehrwert bietet.
Dies hängt häufig mit dem Inhalt zusammen. Schwache, auf Vorlagen basierende, doppelte oder automatisch generierte Seiten werden von Nutzern möglicherweise als nicht ausreichend nützlich eingestuft. In solchen Fällen möchte Google die Indexgröße nicht auf Kosten von minderwertigen Inhalten erhöhen.
Ein weiterer wichtiger Faktor ist die interne Gewichtung einer Seite. Wenn eine URL nicht genügend interne Links aufweist oder tief in der Seitenstruktur verortet ist, kann sie von Suchmaschinen als unwichtig eingestuft werden. Solche Seiten werden zwar gecrawlt, aber bei der Indexierung nicht priorisiert.
Auch der allgemeine Zustand und die Vertrauenswürdigkeit der Website spielen eine Rolle. Neue Domains, Websites mit kurzer Historie, einer großen Anzahl ähnlicher Seiten oder einer schwachen Architektur können dazu führen, dass Google die Indexierung einiger URLs verzögert, bis zusätzliche Qualitätssignale vorliegen.
Man sollte auch bedenken, dass Google nur über begrenzte Ressourcen zum Crawlen und Indexieren verfügt. Daher verteilt Google seine Aufmerksamkeit auf Millionen von Seiten und wählt diejenigen aus, die es im jeweiligen Moment für relevant und nützlich hält.
Letztendlich ist es kein Fehler, wenn Google eine Seite zwar erkennt, sie aber nicht indexiert. Es ist das Ergebnis eines Algorithmus, der zunächst Informationen über die Seite sammelt, die Indexierungsentscheidung aber separat auf Grundlage der Qualität, der Seitenstruktur und der allgemeinen Vertrauenswürdigkeit der Quelle trifft.










