- Головна
- Питання / Відповідь
- Гарантії, терміни та результати
- Чому Google бачить сторінку, але не індексує її?
Чому Google бачить сторінку, але не індексує її?
Іноді сторінка дійсно знаходиться у полі зору пошукової системи Google, але при цьому не потрапляє в індекс. Це нормальна ситуація і один із найпоширеніших сценаріїв у сучасній SEO-практиці.
Важливо розрізняти три стани: виявлення URL, сканування та індексування. У випадках на кшталт "Discovered - currently not indexed" або "Crawled - currently not indexed" у Google Search Console Google вже знає про існування сторінки і навіть міг її відвідати, але з якихось причин не включив її в індекс.
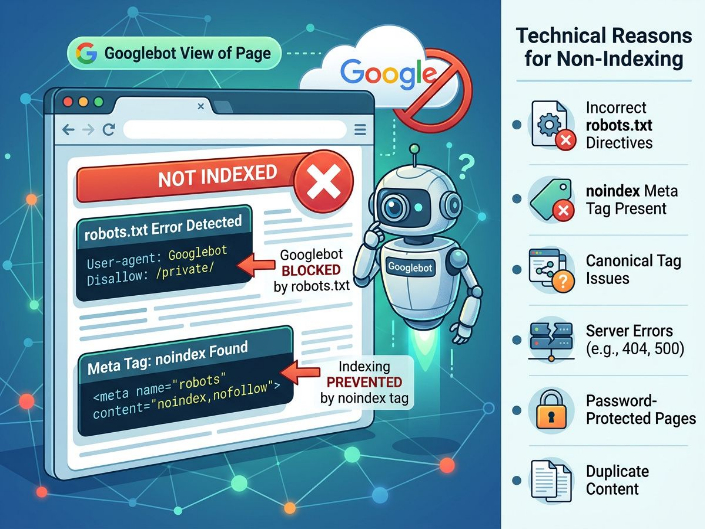
Основна причина такої поведінки – оцінка якості та пріоритетності сторінки. Навіть якщо URL технічно доступна, Google може відкласти або повністю відмовитися від індексації, якщо вважає, що сторінка не додає достатньої цінності порівняно з результатами, що вже існують у пошуку.
Часто це пов'язано із контентом. Слабкі, шаблонні, дубльовані або автоматично згенеровані сторінки можуть бути визнані недостатньо корисними для користувачів. У таких випадках Google вважає за краще не збільшувати обсяг індексу за рахунок низькоцінного контенту.
Інший важливий фактор – внутрішня вага сторінки. Якщо URL не має достатньої кількості внутрішніх посилань або він знаходиться глибоко в структурі сайту, пошукова система може сприймати його як малозначущий. Такі сторінки скануються, але не мають пріоритету для індексації.
Також впливає загальний стан сайту та його довіра. Нові домени, сайти з обмеженою історією, великою кількістю схожих сторінок або слабкою архітектурою можуть стикатися з тим, що Google відкладає індексацію частини URL до отримання додаткових сигналів якості.
Додатково варто враховувати, що Google працює з обмеженими ресурсами обходу та індексування. Тому він розподіляє увагу між мільйонами сторінок, обираючи ті, які вважає найбільш релевантними та корисними на даний момент.
У результаті ситуація , коли Google бачить сторінку, але індексує її, є помилкою. Це результат алгоритмічного відбору, при якому система спочатку збирає інформацію про сторінку, але рішення про включення до індексу приймає окремо, на основі якості, структури сайту та загальної довіри до джерела.










