- Hauptseite
- FAQ
- Weitere Fragen
- Wie wirkt sich die Verwendung einer robots.txt-Datei auf die Google-Indexierung aus?
Wie wirkt sich die Verwendung einer robots.txt-Datei auf die Google-Indexierung aus?
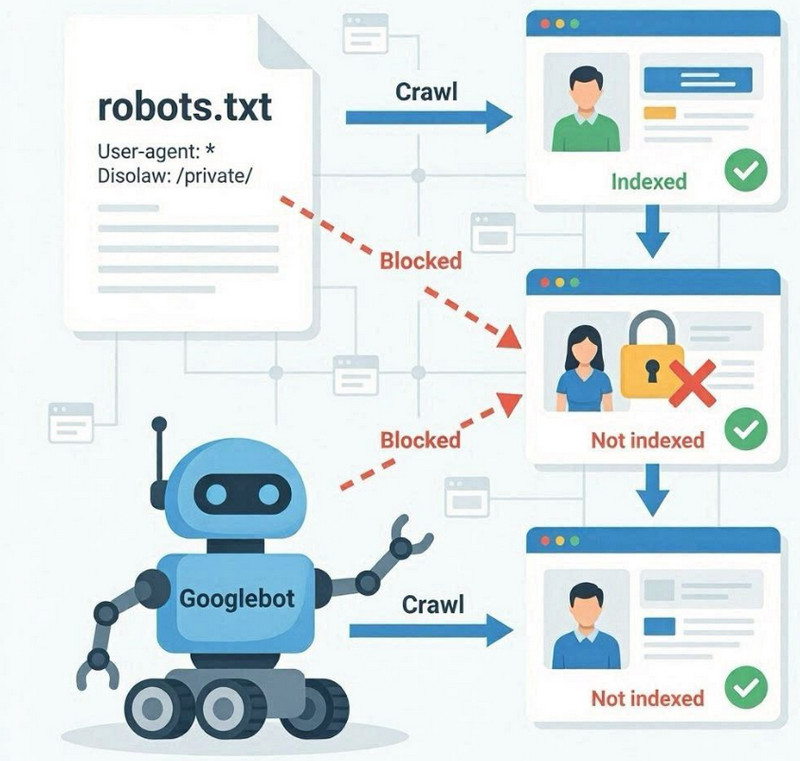
Die robots.txt-Datei ist eine technische Datei im Stammverzeichnis einer Website, die Regeln für Suchmaschinen-Bots festlegt, welche Bereiche gecrawlt und welche ignoriert werden sollen. Ihre Hauptfunktion besteht darin, das Crawling zu steuern, nicht Seiten direkt zu indexieren.
Wenn der Googlebot auf eine Website zugreift, prüft er zunächst die robots.txt-Datei. Sind dort Einschränkungen über die Disallow -Anweisung festgelegt, kann der Bot bestimmte Bereiche oder URLs nicht aufrufen. Das bedeutet, dass diese Seiten nicht gecrawlt werden und ihr Inhalt somit nicht vollständig für die Indexierung verarbeitet wird.
Der Unterschied zwischen Crawling und Indexierung
Die robots.txt-Datei verhindert nicht direkt die Indexierung. Sie schränkt lediglich den Zugriff für das Crawling ein. Dies ist ein wichtiger Unterschied: Eine Seite kann Google zwar durch externe Links oder interne Erwähnungen bekannt sein, aber dennoch nicht gecrawlt werden, wenn der Zugriff verweigert wird.
In solchen Fällen behält Google die URL möglicherweise in seinem Index, ohne den Inhalt vollständig zu analysieren, was zu einer eingeschränkten oder falschen Interpretation der Seite in den Suchergebnissen führt.
Risiken einer fehlerhaften Konfiguration
Fehler in der robots.txt-Datei können die Sichtbarkeit einer Website erheblich beeinträchtigen. Werden wichtige Bereiche wie Kategorien, Produktseiten oder Artikel versehentlich ausgelassen, können Suchmaschinen diese nicht crawlen. Dies führt dazu, dass diese Seiten im Index fehlen oder nur unvollständig indexiert werden.
Das Blockieren von Ressourcen (CSS, JavaScript) ist ebenfalls ein schwerwiegender Fehler, da es die korrekte Darstellung der Seite verhindert. Dies kann zu einer negativen Bewertung der Qualität und Struktur von Inhalten durch Google führen.
Verwendung von robots.txt zur Optimierung des Crawlings
Bei korrekter Konfiguration trägt diese Datei zu einer effizienten Verteilung des Crawling-Budgets bei. Durch das Deaktivieren von Serviceseiten, Filtern, URL-Parametern und Duplikaten kann sich die Suchmaschine auf die wichtigsten Seiten der Website konzentrieren.
Dies ist besonders wichtig für große Websites, bei denen die Anzahl der Seiten Tausende oder Millionen betragen kann und eine Suchmaschine sie physisch nicht alle in einem Zyklus durchsuchen kann.
Die robots.txt-Datei beeinflusst somit die Indexierung, indem sie den Crawling-Zugriff steuert: Sie bestimmt, welche Seiten Google untersuchen kann und welche davon potenziell indexiert und in die Suchergebnisse aufgenommen werden.










