- Ana
- SSS
- Diğer sorular
- Robots.txt dosyasının kullanımı Google indekslemesini nasıl etkiler?
Robots.txt dosyasının kullanımı Google indekslemesini nasıl etkiler?
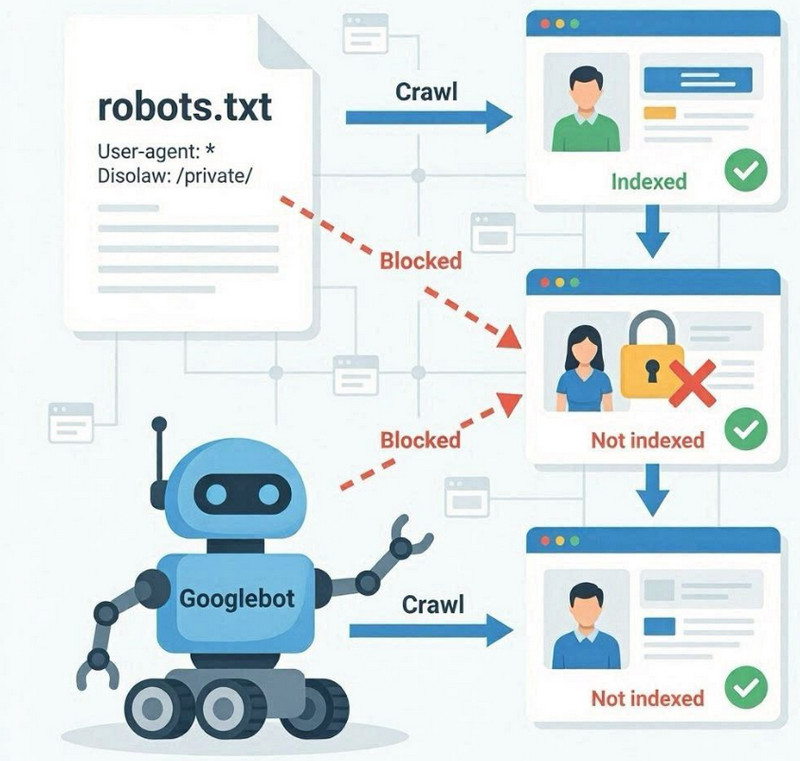
Robots.txt dosyası, bir web sitesinin kök dizininde bulunan ve arama motoru botlarının hangi bölümleri tarayabileceği ve hangilerinin göz ardı edilmesi gerektiği konusunda kurallar belirleyen teknik bir dosyadır. Temel işlevi, sayfaları doğrudan indekslemek değil, taramayı kontrol etmektir.
Googlebot bir web sitesine eriştiğinde, öncelikle robots.txt dosyasını kontrol eder. Eğer Disallow yönergesi aracılığıyla kısıtlamalar belirtilmişse, robot belirli bölümlere veya URL'lere erişemeyebilir. Bu, söz konusu sayfaların taranmayacağı ve içeriklerinin indeksleme için tam olarak işlenmeyeceği anlamına gelir.
Tarama ve indeksleme arasındaki fark
Robots.txt doğrudan indekslemeyi engellemez. Tarama erişimini kısıtlar. Bu önemli bir ayrımdır: Bir sayfa Google tarafından harici bağlantılar veya dahili bahsetmeler yoluyla biliniyor olabilir, ancak erişim engellenirse yine de taranmayabilir.
Bu gibi durumlarda Google, içeriği tam olarak analiz etmeden URL'yi dizininde tutabilir; bu da arama sonuçlarında sayfanın sınırlı veya yanlış yorumlanmasına yol açar.
Yanlış yapılandırmanın riskleri
Robots.txt dosyasındaki hatalar bir web sitesinin görünürlüğünü önemli ölçüde etkileyebilir. Kategoriler, ürün sayfaları veya makaleler gibi önemli bölümler yanlışlıkla atlanırsa, arama motorları bunları tarayamaz. Bu da bu sayfaların dizinde yer almamasına veya eksik dizine eklenmesine neden olur.
Kaynakların (CSS, JavaScript) engellenmesi de kritik bir hatadır, çünkü sayfanın doğru şekilde görüntülenmesini engeller. Bu durum, Google'ın içeriğin kalitesi ve yapısı hakkındaki değerlendirmesinin olumsuz olmasına yol açabilir.
robots.txt kullanarak taramayı optimize etme
Doğru şekilde yapılandırıldığında, bu dosya tarama bütçesinin verimli bir şekilde tahsis edilmesine yardımcı olur. Servis sayfalarını, filtreleri, URL parametrelerini ve yinelenen kayıtları devre dışı bırakmak, arama motorunun sitenin en önemli sayfalarına odaklanmasını sağlar.
Bu durum, sayfa sayısı binlerce veya milyonlarca olabilen ve bir arama motorunun tek bir döngüde tüm sayfaları tarayamayacağı büyük siteler için özellikle önemlidir.
Dolayısıyla, robots.txt dosyası tarama erişimini kontrol ederek indekslemeyi etkiler: Google'ın hangi sayfaları inceleyebileceğini ve dolayısıyla hangilerinin potansiyel olarak indeksleneceğini ve arama sonuçlarına dahil edileceğini belirler.










