- मुख्य
- FAQ
- अन्य प्रश्न
- robots.txt फ़ाइल का उपयोग करने से Google इंडेक्सिंग पर क्या प्रभाव पड़ता है?
robots.txt फ़ाइल का उपयोग करने से Google इंडेक्सिंग पर क्या प्रभाव पड़ता है?
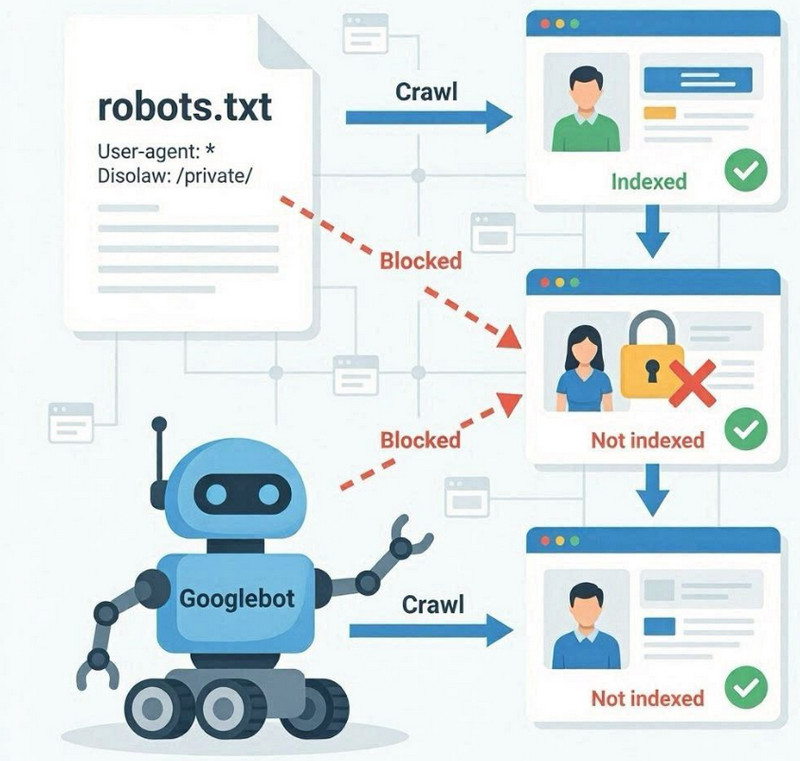
robots.txt फ़ाइल वेबसाइट के रूट में स्थित एक तकनीकी फ़ाइल है जो सर्च इंजन बॉट्स के लिए नियम निर्धारित करती है कि किन अनुभागों को क्रॉल किया जा सकता है और किनको अनदेखा किया जाना चाहिए। इसका मुख्य कार्य क्रॉलिंग को नियंत्रित करना है, न कि सीधे पेजों को इंडेक्स करना।
जब Googlebot किसी वेबसाइट पर जाता है, तो वह सबसे पहले robots.txt फ़ाइल की जाँच करता है। यदि इसमें 'Disallow' निर्देश के माध्यम से प्रतिबंध निर्दिष्ट हैं, तो रोबोट कुछ अनुभागों या URL तक नहीं पहुँच सकता है। इसका अर्थ है कि ऐसे पृष्ठों को क्रॉल नहीं किया जाएगा, यानी उनकी सामग्री को इंडेक्सिंग के लिए पूरी तरह से संसाधित नहीं किया जाएगा।
क्रॉलिंग और इंडेक्सिंग के बीच का अंतर
Robots.txt सीधे तौर पर इंडेक्सिंग को नहीं रोकता है। यह क्रॉलिंग की पहुँच को सीमित करता है। यह एक महत्वपूर्ण अंतर है: कोई पेज बाहरी लिंक या आंतरिक उल्लेखों के माध्यम से Google को ज्ञात हो सकता है, लेकिन पहुँच से इनकार किए जाने पर भी उसे क्रॉल नहीं किया जा सकता है।
ऐसे मामलों में, Google सामग्री का पूरी तरह से विश्लेषण किए बिना URL को अपने इंडेक्स में रख सकता है, जिससे खोज में पृष्ठ की सीमित या गलत व्याख्या हो सकती है।
गलत कॉन्फ़िगरेशन के जोखिम
robots.txt में त्रुटियां वेबसाइट की दृश्यता पर काफी असर डाल सकती हैं। यदि श्रेणियां, उत्पाद पृष्ठ या लेख जैसे महत्वपूर्ण अनुभाग गलती से छूट जाते हैं, तो खोज इंजन उन्हें क्रॉल नहीं कर पाएंगे। इसके परिणामस्वरूप ये पृष्ठ इंडेक्स से गायब हो जाते हैं या अपूर्ण रूप से इंडेक्स हो पाते हैं।
संसाधनों (CSS, JavaScript) को अवरुद्ध करना भी एक गंभीर त्रुटि है, क्योंकि यह पृष्ठ को सही ढंग से प्रदर्शित होने से रोकता है। इसके परिणामस्वरूप Google द्वारा सामग्री की गुणवत्ता और संरचना का गलत मूल्यांकन हो सकता है।
क्रॉलिंग को अनुकूलित करने के लिए robots.txt का उपयोग करना
सही तरीके से कॉन्फ़िगर किए जाने पर, यह फ़ाइल क्रॉल बजट को कुशलतापूर्वक आवंटित करने में मदद करती है। सर्विस पेज, फ़िल्टर, यूआरएल पैरामीटर और डुप्लिकेट को अक्षम करने से सर्च इंजन साइट के सबसे महत्वपूर्ण पेजों पर ध्यान केंद्रित कर पाता है।
यह विशेष रूप से बड़ी वेबसाइटों के लिए महत्वपूर्ण है जहां पृष्ठों की संख्या हजारों या लाखों में हो सकती है, और एक खोज इंजन भौतिक रूप से एक ही चक्र में उन सभी को क्रॉल नहीं कर सकता है।
इस प्रकार, robots.txt क्रॉल एक्सेस को नियंत्रित करके इंडेक्सिंग को प्रभावित करता है: यह निर्धारित करता है कि Google किन पृष्ठों की जांच कर सकता है, और इसलिए उनमें से कौन से संभावित रूप से इंडेक्स किए जाएंगे और खोज परिणामों में शामिल किए जाएंगे।










