- मुख्य
- FAQ
- अनुक्रमणिका के बारे में सामान्य प्रश्न
- वेबसाइट के पेज लंबे समय तक इंडेक्स क्यों नहीं हो पाते?
वेबसाइट के पेज लंबे समय तक इंडेक्स क्यों नहीं हो पाते?
वेबसाइट के पेज कई कारणों से लंबे समय तक इंडेक्स नहीं हो पाते हैं, और अधिकतर मामलों में यह कोई एक समस्या नहीं बल्कि कई कारकों का संयोजन होता है। Google या Yandex जैसे सर्च इंजन हर पेज को इंडेक्स करने के लिए बाध्य नहीं होते हैं—वे केवल उन्हीं URL को चुनते हैं जिन्हें वे उपयोगी और उच्च गुणवत्ता वाला मानते हैं।
इसका एक सबसे आम कारण कमजोर आंतरिक लिंकिंग है। यदि किसी पेज को साइट के अन्य अनुभागों से लिंक नहीं किया जाता है, तो सर्च इंजन के लिए उसे ढूंढना और उसके महत्व को समझना मुश्किल हो जाता है। ऐसे पेज अक्सर निष्क्रिय पड़े रहते हैं, सर्च इंजन रैंकिंग में उनकी कोई भूमिका नहीं होती, और लंबे समय तक उन्हें अनदेखा किया जा सकता है।
दूसरा महत्वपूर्ण कारक क्रॉल बजट है। हर वेबसाइट के पास सीमित संसाधन होते हैं जिन्हें सर्च इंजन क्रॉल करने के लिए खर्च करने को तैयार होते हैं। यदि किसी साइट में हजारों या लाखों यूआरएल हैं (उदाहरण के लिए, फ़िल्टर, पैरामीटर, डुप्लिकेट), तो क्रॉलर कम महत्वपूर्ण पेजों पर समय बर्बाद कर सकता है, जिससे उसे आवश्यक पेज नहीं मिल पाते। परिणामस्वरूप, कुछ यूआरएल या तो विलंबित हो जाते हैं या पूरी तरह से अनदेखा कर दिए जाते हैं।
तकनीकी त्रुटियाँ भी एक आम कारण हैं। यदि कोई पृष्ठ अस्थिर सर्वर प्रतिक्रिया देता है, लोड होने में अधिक समय लेता है, HTML त्रुटियाँ रखता है, या परस्पर विरोधी निर्देश (उदाहरण के लिए, एक मानक URL किसी अन्य URL की ओर इंगित करता है जबकि पृष्ठ इंडेक्सिंग के लिए खुला है) शामिल करता है, तो खोज इंजन इसकी इंडेक्सिंग में देरी कर सकता है या इसे रद्द कर सकता है। Robots.txt प्रतिबंध या noindex मेटा टैग का भी ऐसा ही प्रभाव होता है।
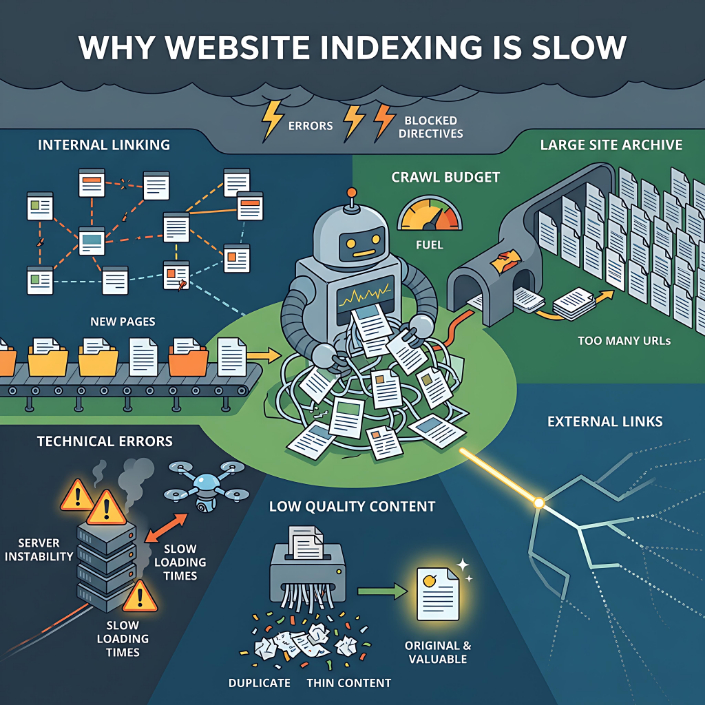
सामग्री की गुणवत्ता पर विशेष ध्यान देना आवश्यक है। भले ही कोई पृष्ठ सुलभ हो और तकनीकी रूप से सही ढंग से कॉन्फ़िगर किया गया हो, फिर भी यदि खोज इंजन उसे कम उपयोगी समझता है तो उसे इंडेक्स में शामिल नहीं किया जा सकता है। यह बात डुप्लिकेट पृष्ठों, स्वचालित रूप से उत्पन्न सामग्री, कम जानकारी वाले पृष्ठ या विशिष्ट विवरण के बिना सामान्य उत्पाद पृष्ठों पर लागू होती है। ऐसे मामलों में, खोज इंजन पृष्ठ को क्रॉल तो कर सकता है लेकिन उसे इंडेक्स में शामिल नहीं करेगा।
बाहरी संकेत भी महत्वपूर्ण होते हैं। यदि किसी पृष्ठ में कोई बाहरी लिंक नहीं है और साइट के बाहर उसका उल्लेख नहीं है, तो तेजी से इंडेक्सिंग होने की संभावना कम हो जाती है। सर्च इंजन पृष्ठों के महत्व का पता लगाने और मूल्यांकन करने के लिए लिंक को प्रमुख संकेतों में से एक के रूप में उपयोग करते हैं।
ऑनलाइन स्टोर, कैटलॉग, एग्रीगेटर और समाचार परियोजनाओं जैसी जटिल संरचना वाली वेबसाइटों में इंडेक्सिंग संबंधी समस्याएं विशेष रूप से आम हैं। इनमें कई समान पेज, फ़िल्टर, यूआरएल भिन्नताएं और गतिशील सामग्री होती हैं। इससे क्रॉलर पर भार पड़ता है और डुप्लिकेट होने का खतरा बढ़ जाता है। नई वेबसाइटों को भी इसी तरह की समस्या का सामना करना पड़ता है—उन्होंने अभी तक सर्च इंजनों के साथ विश्वास स्थापित नहीं किया है, इसलिए इंडेक्सिंग धीमी हो सकती है।
इसके अलावा, एक साथ बड़ी संख्या में नए यूआरएल जोड़ने से भी प्रक्रिया धीमी हो सकती है। सर्च इंजन हमेशा सब कुछ एक साथ प्रोसेस नहीं करते; वे संसाधनों को धीरे-धीरे वितरित करते हैं, खासकर यदि साइट ने पहले लगातार अच्छी गुणवत्ता प्रदर्शित नहीं की हो।
अंततः, धीमी इंडेक्सिंग इस बात का संकेत है कि सर्च इंजन को पेज तक पहुँचने में कठिनाई हो रही है या उसे पेज में पर्याप्त मूल्य नहीं दिख रहा है। इसलिए, एक प्रभावी रणनीति केवल URL को इंडेक्सिंग के लिए "पुश" करना नहीं है, बल्कि साथ ही साथ कंटेंट की गुणवत्ता, साइट संरचना, इंटरलिंकिंग और तकनीकी स्थिति पर भी ध्यान देना है।










