- Main
- FAQ
- General questions about indexing
- Why might website pages not be indexed for a long time?
Why might website pages not be indexed for a long time?
Website pages may remain unindexed for a long time for various reasons, and in most cases, it's not a single issue but a combination of factors. Search engines like Google or Yandex aren't required to index every page they find—they only select URLs they consider useful and high-quality.
One of the most common causes is weak internal linking. If a page isn't linked to from other sections of the site, it's harder for search engines to discover it and understand its importance. Such pages often remain idle, without any search engine ranking power, and can be ignored for long periods of time.
The second important factor is crawl budget. Every website has a limited amount of resources that search engines are willing to spend on crawling it. If a site has thousands or millions of URLs (for example, filters, parameters, duplicates), the crawler may waste time on less important pages, missing out on the ones they need. As a result, some URLs are either delayed or ignored entirely.
Technical errors are another common cause. If a page returns an unstable server response, takes a long time to load, contains HTML errors, or contains conflicting directives (for example, a canonical URL points to a different URL while the page is open for indexing), the search engine may delay or cancel its indexing. Robots.txt restrictions or the noindex meta tag have a similar effect.
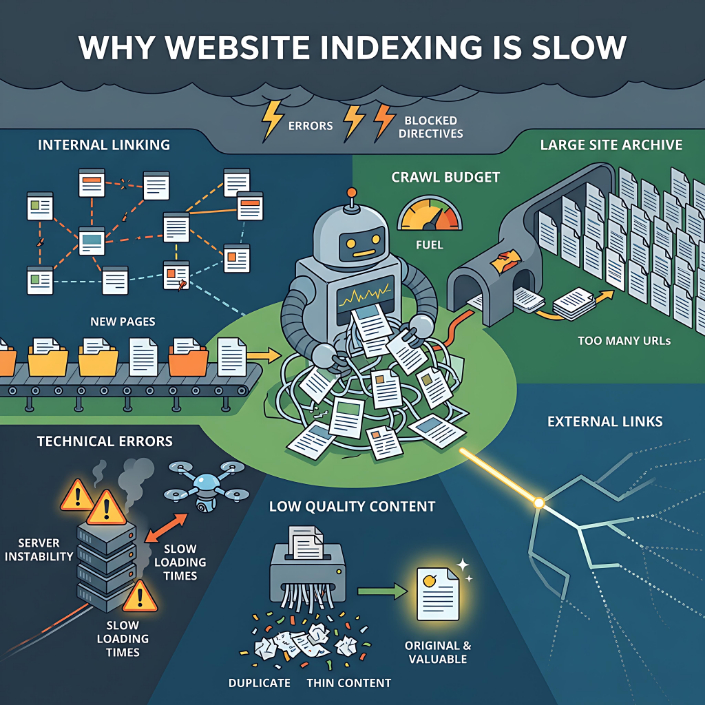
Content quality deserves special attention. Even if a page is accessible and technically correctly configured, it may not be indexed if the search engine deems it of little use. This applies to duplicate pages, automatically generated content, thin content pages with minimal information, or generic product pages without a unique description. In such cases, the search engine may crawl the page but not include it in the index.
External signals are also important. If a page has no external links and is not mentioned outside the site, the likelihood of rapid indexing decreases. Search engines use links as one of the key signals for detecting and evaluating the importance of pages.
Indexing issues are especially common among websites with complex structures, such as online stores, catalogs, aggregators, and news projects. They have many similar pages, filters, URL variations, and dynamic content. This creates a load on crawlers and increases the risk of duplicates. Young websites face a similar situation—they haven't yet established trust with search engines, so indexing can be slower.
Additionally, a large number of new URLs added simultaneously can also slow down the process. Search engines don't always process everything at once; they distribute resources gradually, especially if the site hasn't previously demonstrated consistent quality.
Ultimately, slow indexing is a signal that the search engine is either having difficulty accessing the page or doesn't see sufficient value in it. Therefore, an effective strategy isn't simply "pushing" URLs for indexing, but simultaneously addressing content quality, site structure, interlinking, and technical condition.










